Functions
There are three different kinds of functions:
Processing functions take an event and return a processed event (e.g.
RemoveBaseline), and they are meant to be used on event iterators:
it = vai.MockData().get_event_iterator().with_processing(vai.RemoveBaseline())
Scalar functions take an event and return a scalar (e.g.
MainParametersreturns main parameters). They are meant to be applied to entire iterators using theapplyfunction:
it = vai.MockData().get_event_iterator().with_processing(vai.RemoveBaseline())
mp = vai.apply(vai.MainParameters(dt_us=it.dt_us), it)
A cool thing about scalar functions is that they come with .names() and .dtypes() functions which lets you conveniently arrange the outputs into an easy to read dictionary:
mp_dict = {k: v for k, v in zip(f.names(), mp)}
Utility functions don’t fall into those two categories (e.g.
applyor Trigger functions).
Processing functions
- class cait.versatile.Downsample(down: int = 2)[source]
Downsample an event by a given factor (which has to be a factor of the event’s length). Also works for multiple channels simultaneously.
- Parameters:
down (int) – The factor by which to downsample the voltage trace.
- Returns:
Downsampled event.
- Return type:
np.ndarray
Example:
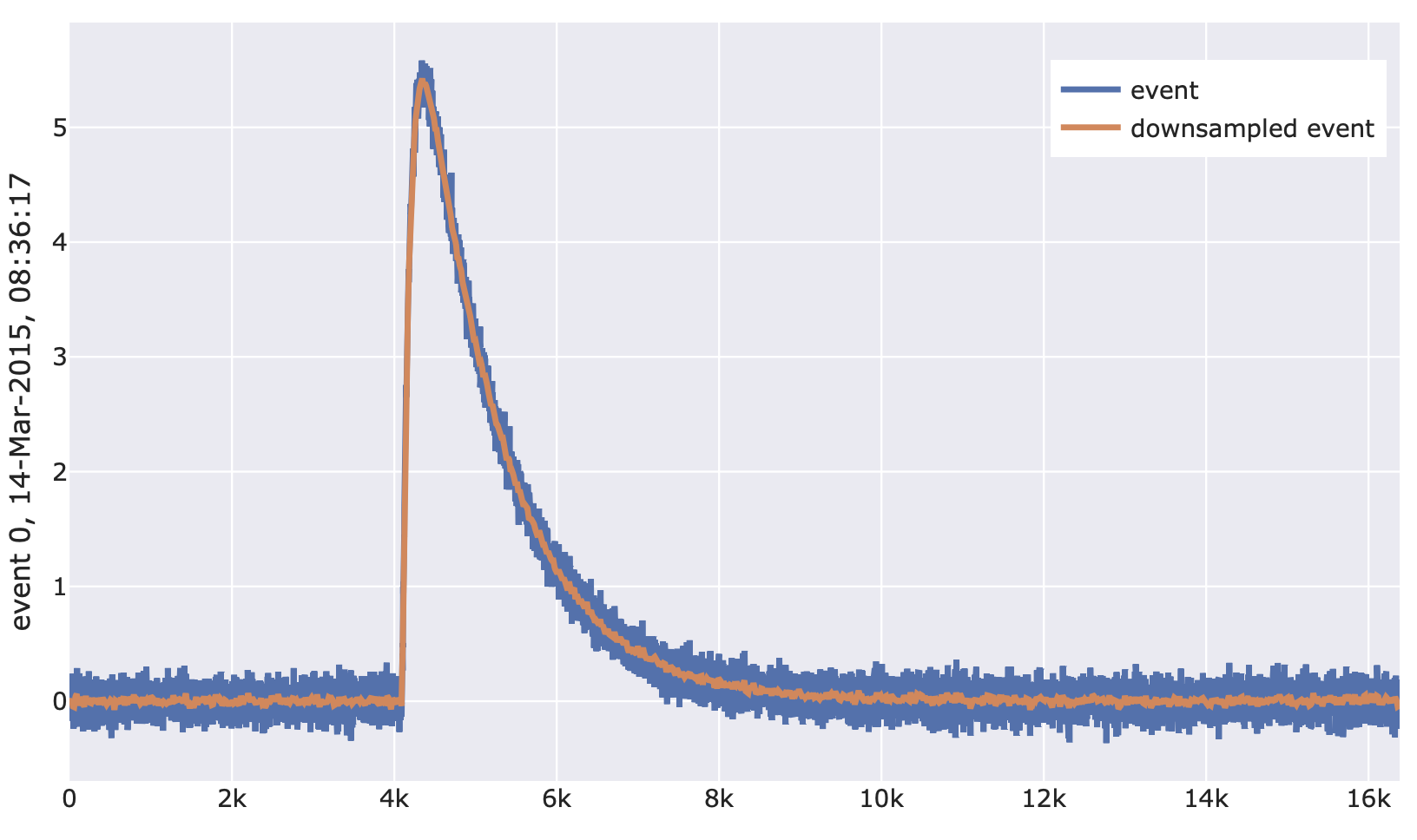
import cait.versatile as vai # Construct mock data (which provides event iterator) md = vai.MockData() it = md.get_event_iterator()[0].with_processing(vai.RemoveBaseline()) # View effect of downsample on events vai.Preview(it, vai.Downsample(16))
- class cait.versatile.RemoveBaseline(fit_baseline: dict = {'model': 0, 'where': 0.125, 'xdata': None})[source]
Remove baseline of given baseline model from an event voltage trace and return the new event. Also works for multiple channels simultaneously.
- Parameters:
fit_baseline (dict) – Dictionary of keyword arguments that are passed on to
FitBaseline.- Returns:
Event with baseline removed
- Return type:
numpy.ndarray
Example:
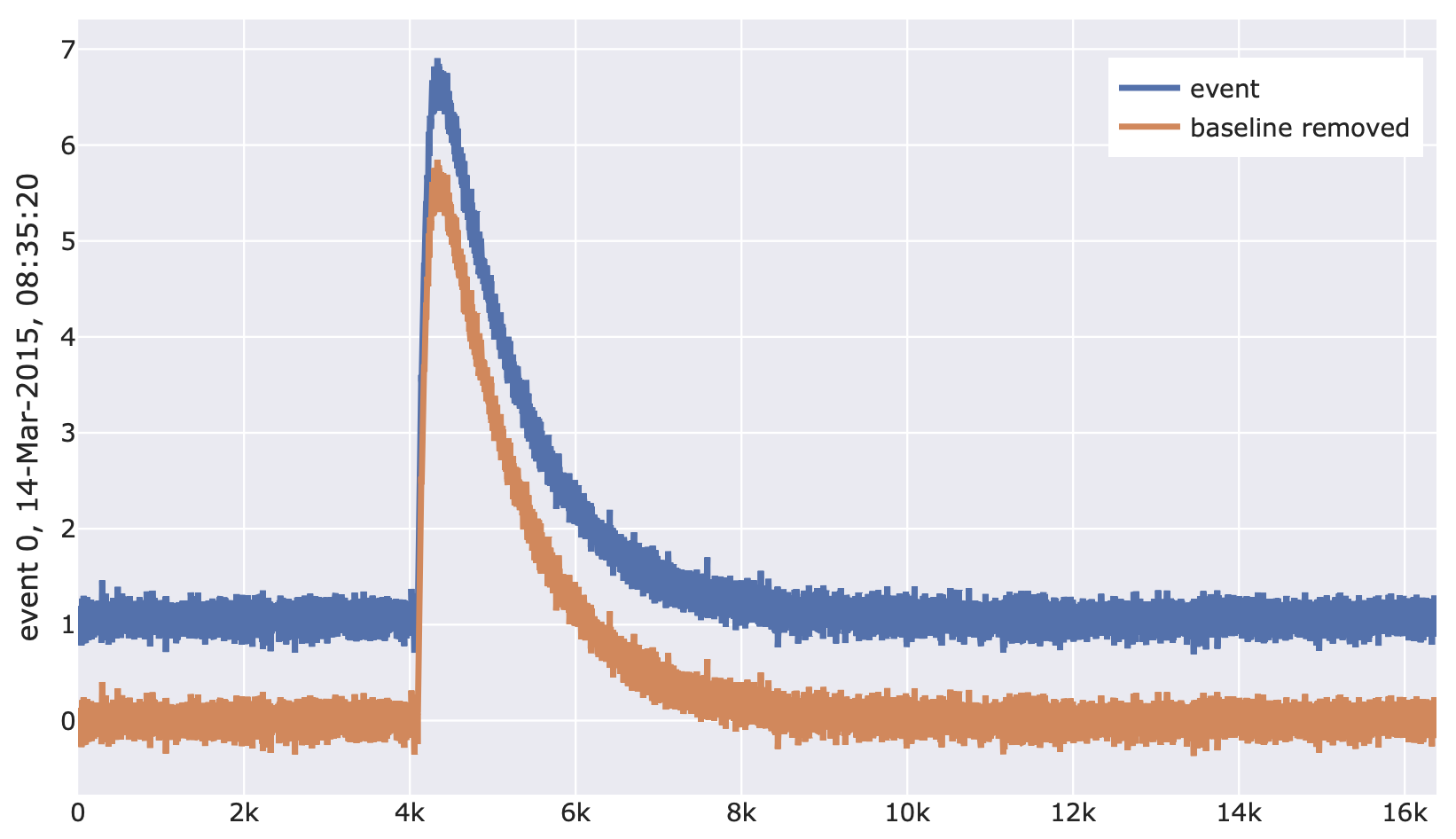
import cait.versatile as vai # Construct mock data (which provides event iterator) md = vai.MockData() it = md.get_event_iterator()[0] # View effect of removing baseline on events vai.Preview(it, vai.RemoveBaseline())
- class cait.versatile.BoxCarSmoothing(length: int = 50)[source]
Apply box-car-smoothing (moving average) to a voltage trace. Also works for multiple channels simultaneously.
- Parameters:
length (int) – Length (in samples) of the moving average. Defaults to 50.
- Returns:
Smoothed event.
- Return type:
np.ndarray
Example:
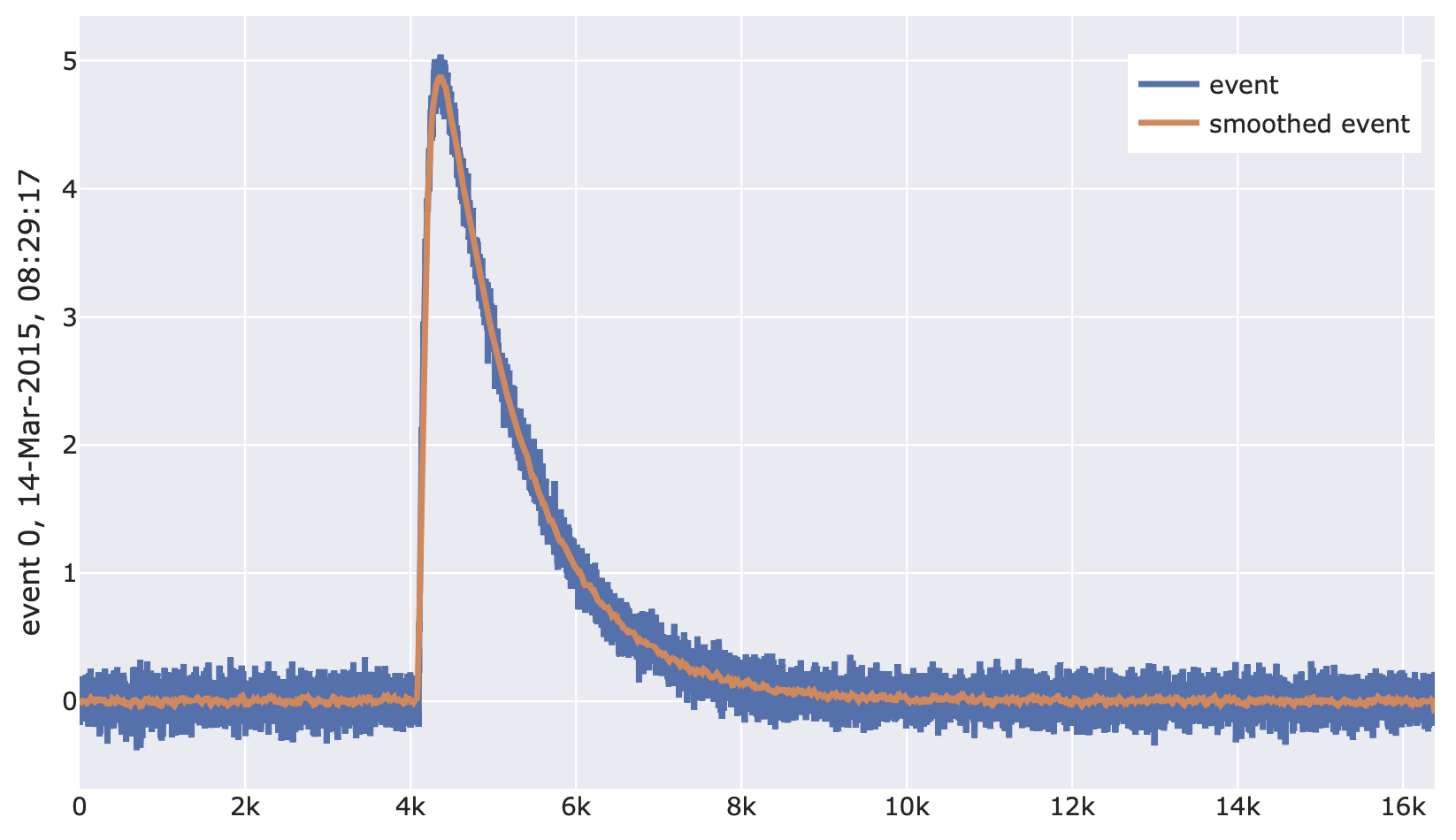
import cait.versatile as vai # Construct mock data (which provides event iterator) md = vai.MockData() it = md.get_event_iterator()[0].with_processing(vai.RemoveBaseline()) # View effect of moving average on events vai.Preview(it, vai.BoxCarSmoothing())
- class cait.versatile.TukeyWindow(alpha: float = 0.25)[source]
Apply the Tukey window function to a voltage trace. Also works for multiple channels simultaneously.
- Parameters:
alpha (float) – The parameter of the Tukey window function. Defaults to 0.25.
- Returns:
Event with applied window function.
- Return type:
np.ndarray
Example:
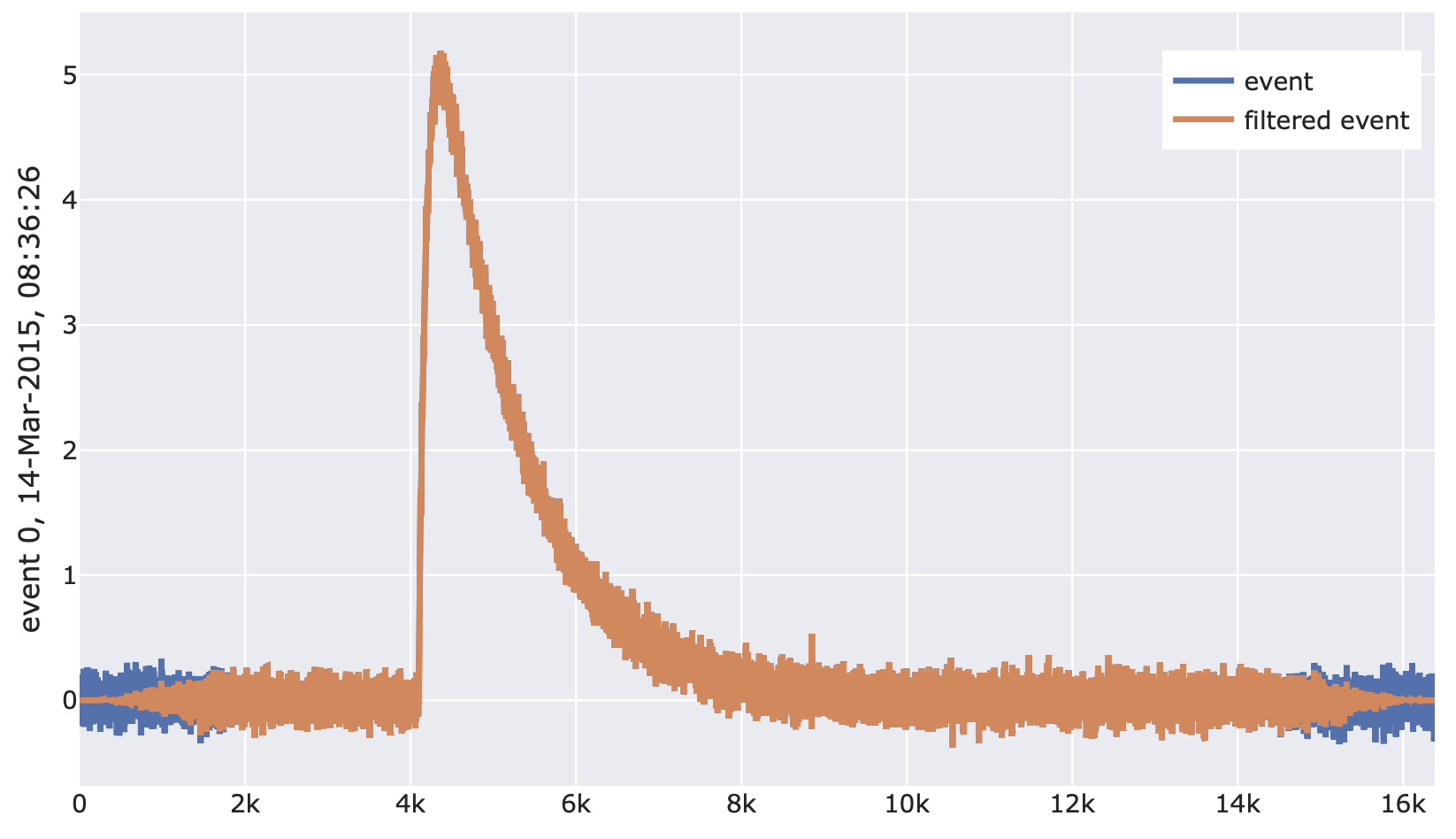
import cait.versatile as vai # Construct mock data (which provides event iterator) md = vai.MockData() it = md.get_event_iterator()[0].with_processing(vai.RemoveBaseline()) # View effect of filtering on events vai.Preview(it, vai.TukeyWindow())
- class cait.versatile.OptimumFiltering(of: ndarray, method: str = 'circular')[source]
Apply an optimum filter to a voltage trace. Works for multiple channels simultaneously if optimum filter is also given for multiple channels.
- Parameters:
of (np.ndarray) – The optimum filter to use.
method (str) – The method by which the filter is convolved with an event. Can be either ‘circular’ in which case the event is Fourier transformed, multiplied by the filter kernel, and back transformed, ‘linear’ in which case the event is convolved without warp-around (samples which would require wrap-around are removed), and ‘linear_pad’ which is the same as ‘linear’ but the trace is first zero-padded (retaining the same number of samples in the output trace). ‘linear’ and ‘linear_pad’ also support events that are larger than the filter kernel permits in the ‘circular’ case. Defaults to ‘circular’.
- Returns:
Filtered event.
- Return type:
np.ndarray
Warning
For filters that were built from a SEV whose maximum is not aligned at 1/4th of the record window, methods ‘circular’ and ‘linear’ might yield different results. In particular, the peak positions of the filtered traces might be offset. When using ‘linear’, it is recommended to have the SEV’s maximum aligned at 1/4th of the record window.
Warning
When choosing to zero-pad your events (method ‘linear_pad’), you should first remove any constant baseline from your event traces (
it.with_processing(vai.RemoveBaseline())).Example:
import cait.versatile as vai # Construct mock data (which provides event iterator and optimum filter) md = vai.MockData() it = md.get_event_iterator()[0].with_processing(vai.RemoveBaseline()) of = md.of[0] # View effect of filtering on events vai.Preview(it, vai.OptimumFiltering(of))
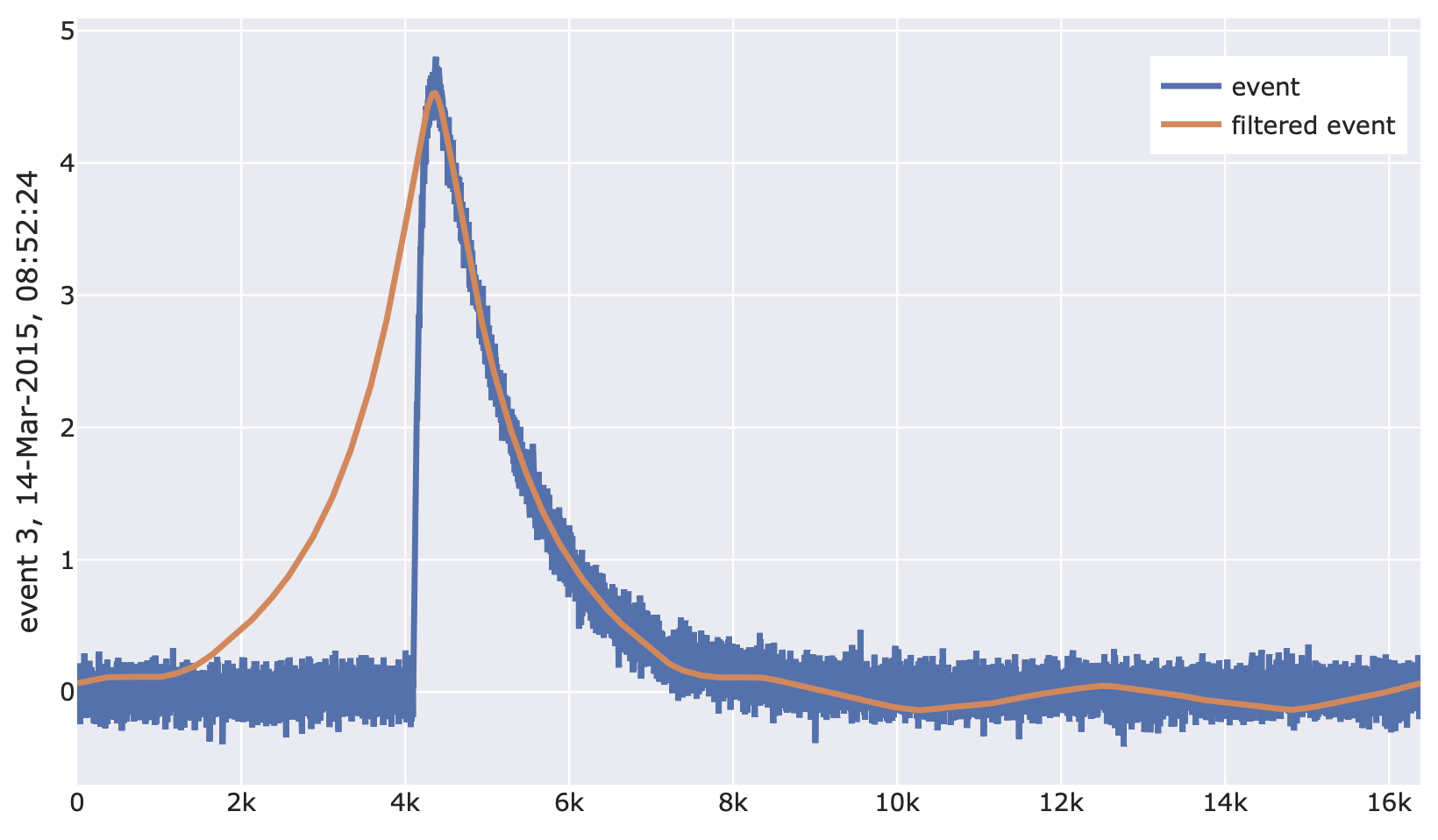
- class cait.versatile.OptimumFiltering2D(of: ndarray, **kwargs)[source]
Apply a 2D optimum filter to multi-channel voltage traces. Regardless of the number of input channels, this function always returns a single, combined channel result.
Equivalent to regular
OptimumFilteringall the channels and summing the result. In general, this only makes sense if you built the multi-channel OF from a Noise Covariance Matrix (cait.versatile.NCM), i.e. when the OF incorporates information from all the channels.- Parameters:
of (np.ndarray) – The optimum filter to use.
kwargs (Any) – Additional keyword arguments for
cait.versatile.OptimumFiltering.
- Returns:
Filtered event.
- Return type:
np.ndarray
- class cait.versatile.FluxQuantumLossCorrection(method: str = 'mmd', fql_voltage: float = None, thresh: float = 0.2, true_pulseheight: float = None, return_shift_value: bool = False)[source]
Correct event for flux quantum loss (FQL). Works only for one channel at a time.
- Parameters:
method (str) – One of three methods: “mmd”, “slope” or “true_ph”. “mmd” (mininmum-minimum difference) calculates the FQL as difference between the minima before and after the pulse (with some fluctuation mitigation). “slope” calculates the FQL as the slope of the event. “true_ph” assumes that the true pulse height (without FQL) is known - and provided in the parameter true_pulseheight - and calculates the FQL as the difference between true and apparent pulse height. Defaults to the recommended “mmd”.
fql_voltage (float, optional) – If the voltage drop of an FQL is known and provided here, the correction shift will be an integer multiple of this value, instead of any value. In this case, the number of FQ lost is determined by subtracting the threshold (param “thresh”) from the calculated shift and then rounding up to an integer multiple of fql_voltage. Defaults to None.
thresh (float) – Minimum shift value to accept as FQL and correct for. Smaller or negative values are assumed to not stem from FQLs. Defaults to 0.2 V.
true_pulseheight (float, optional) – The known true pulse height as defined by the maximum possible pulse height for fully saturated pulses. Necessary for method “true_ph”. Defaults to None.
return_shift_value (bool) – If True, not the shifted event, but instead the shift value is returned. Defaults to False.
- Returns:
Event with FQL corrected, or value of shift if return_shift_value is set to True.
- Return type:
Union[numpy.ndarray, float]
Example:
import numpy as np import cait.versatile as vai # Get events and SEV from mock data (and select first channel) md = vai.MockData() sev = md.sev[0] events = md.get_event_iterator()[0].with_processing(vai.RemoveBaseline()) # Define a function that (roughly) mimics events with FQL. # (This is of course only needed to make this example # self-contained. You would have actual data for such events.) SHIFT = 3 def mock_fql(event): fake_event = event.copy() ph = np.max(fake_event) flag = fake_event > ph - SHIFT fake_event[flag] = ph - SHIFT k = np.argmax(flag[::-1]) fake_event[-k:] += ph*sev[-k:]/np.max(sev[-k:]) - vai.BoxCarSmoothing()(fake_event)[-k:] - SHIFT return fake_event # Add this function as processing (to fake FQL events). # Again, you don't need this because you have FQL data. events = events.with_processing(mock_fql) # Preview the working of the FQL correction vai.Preview(events, vai.FluxQuantumLossCorrection()) # Or calculate the shift value by setting 'return_shift_value=True'. # The result are values close to 3, i.e. the one we 'simulated' shift_values = vai.apply(vai.FluxQuantumLossCorrection(return_shift_value=True), events) # Check the distribution of shift values vai.Histogram(shift_values)
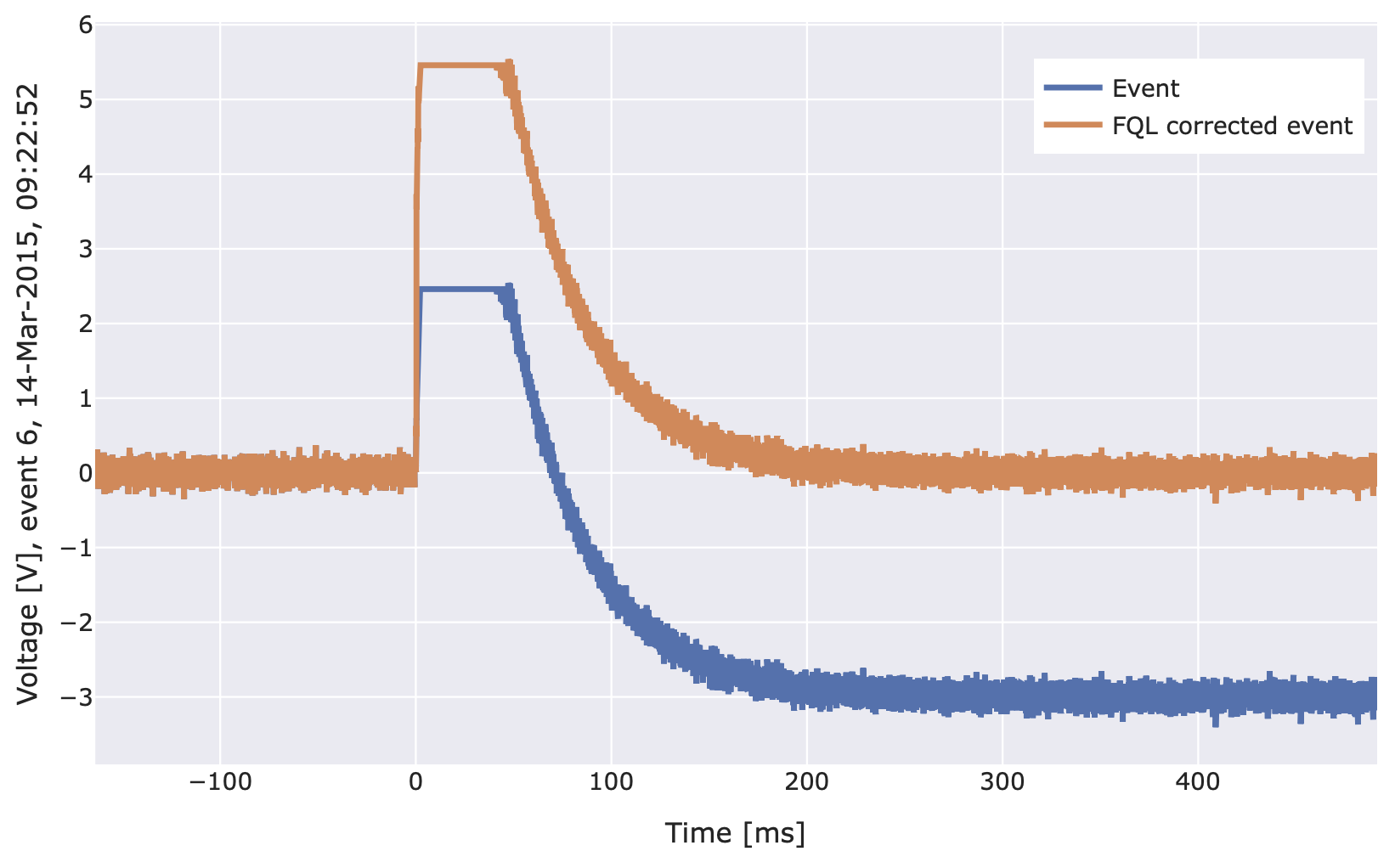
Scalar functions
- class cait.versatile.FitBaseline(model: int | str = 0, where: List[bool] | slice | float = slice(None, None, None), xdata: List[float] = None)[source]
Fit voltage traces with a polynomial or decaying exponential and return the fit parameters as well as the RMS. Also works for multiple channels simultaneously.
- Parameters:
model (Union[int, str]) – Order of the polynomial, ‘exponential’/’exp’ (exponential baseline model; in the case of a failed fit, falls back to constant baseline, i.e. model=0), or ‘voltage_minimum’ (subtracting a constant value, which is close to the minimum of the voltage trace before the pulse – with some fluctuation mitigation. This works better than the standard method when there is a pileup in the pre-trigger region), defaults to 0, i.e. a constant baseline.
where (Union[List[bool], slice, float]) – Specifies a subset of data points to be used in the fit: Either a boolean flag of the same length of the voltage traces, a slice object (e.g. slice(0,50) for using the first 50 data points), or a float. If a float where is passed, the first int(where*record_length) samples are used (e.g. if where=1/8, the first 1/8th of the record window is used). Defaults to slice(None, None, None).
xdata (List[float]) – x-data to use for the fit (has no effect for order=0). Specifying xdata is not necessary in general but if you want your fit parameters to have physical units (e.g. time constants) instead of just samples, you may use this option. Defaults to None, in which case xdata=np.linspace(0,1,record_length).
- Returns:
Fit parameter(s) and RMS as a tuple.
- Return type:
Tuple[Union[float, numpy.ndarray], float]
Example:
import cait.versatile as vai # Construct mock data (which provides event iterator) md = vai.MockData() it = md.get_event_iterator()[0] # View effect of fitting baseline on events # We specify that for the fit, 1/8th of the record window should be used, # that we fit with a degree-0-polynomial (i.e. constant) # Specifying the xdata is not necessary, but it lets us plot in terms of time vai.Preview(it, vai.FitBaseline(where=1/8, model=0, xdata=it.t), xlabel="Time (ms)")
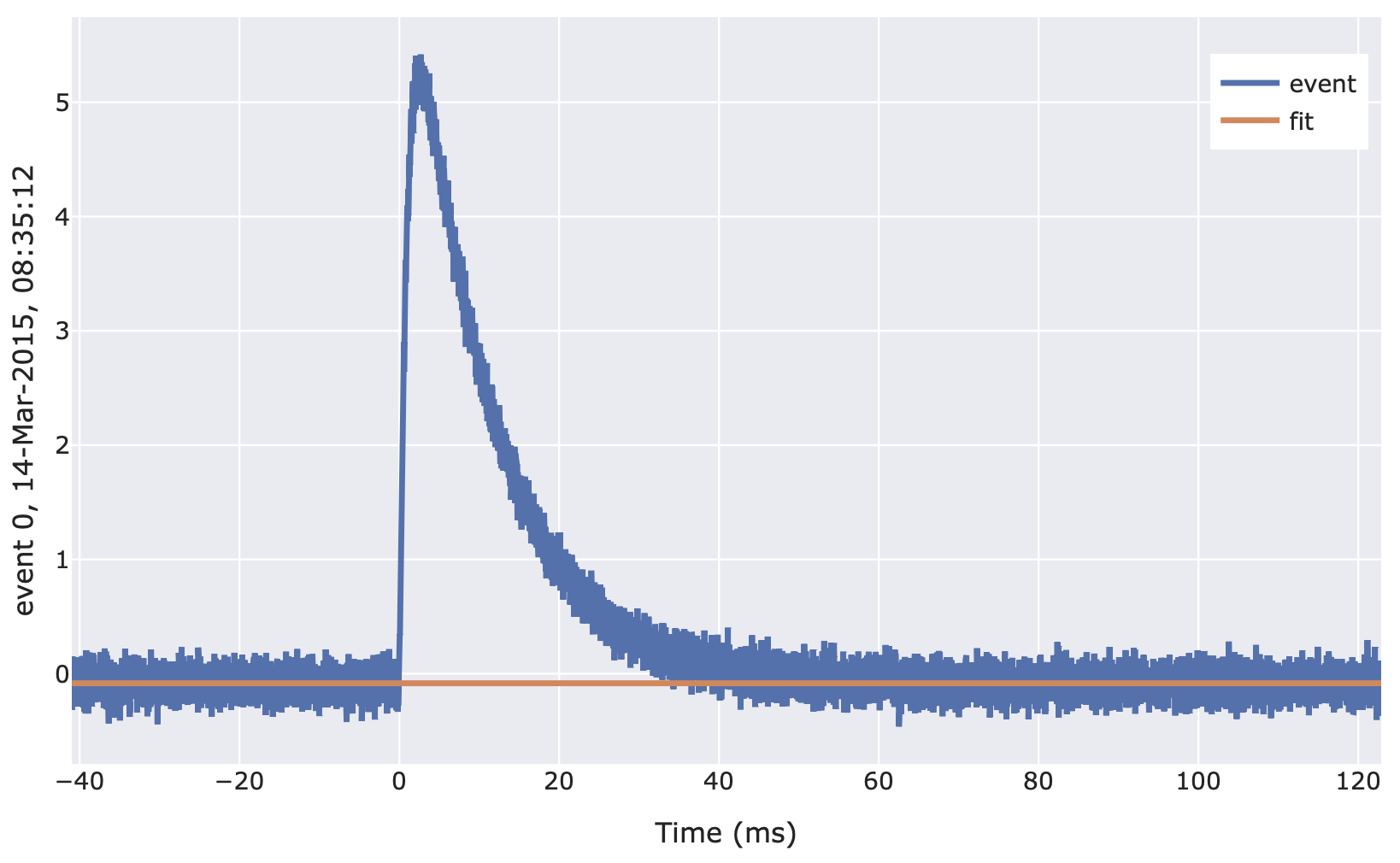
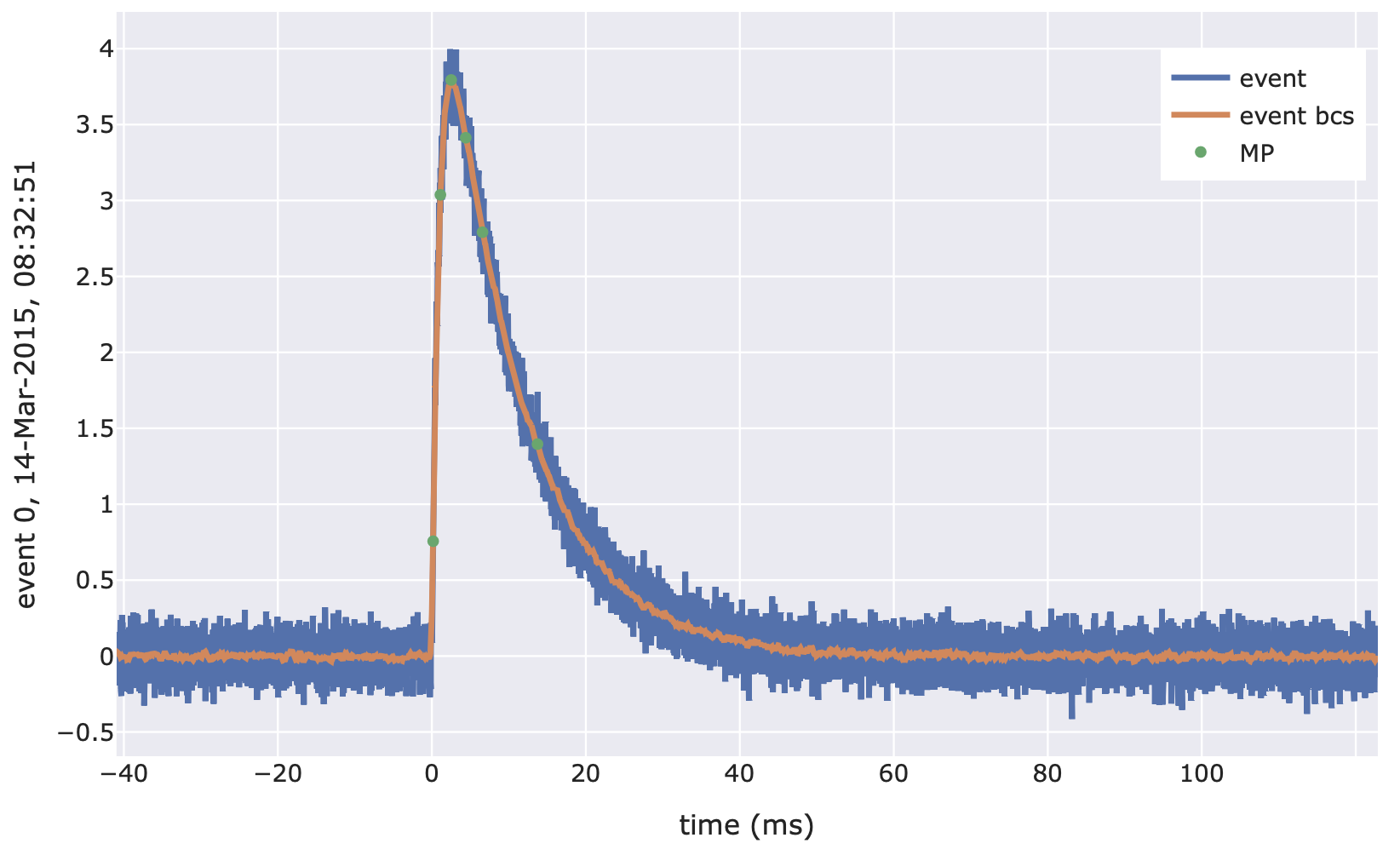
- class cait.versatile.MainParameters(dt_us: int = None, peak_loc: List[float] | List[int] | float | int = [0.2, 0.4], bcs={'length': 50}, fbl={'model': 1, 'where': 0.125})[source]
Calculate main parameters for an event. These parameters are:
pulse height (V): Height of the event
peak position (ms): Position of the peak.
onset (ms): Start of the pulse, which is assumed to be where the trace rises to 20% of the pulse height. This value is shifted relative to 1/4 of the record length, so should be negative for normal pulses.
rise time (ms): Time from onset to reach 80% of the pulse height.
decay time (ms): Time (after pulse maximum) from 90% of pulse height to 36.8% (1/e) of pulse height.
baseline slope (V/samples): Slope of baseline prior to onset, calculated using a fraction of the record length.
baseline offset (V): Offset of the baseline, averaged over a fraction of the record length.
baseline difference (V): Difference between the right and left edges of the trace, averaged over a fraction of the record length.
baseline rms (V): RMS noise of the baseline over a fraction of the record length.
minimum derivative (V): Most negative difference between two samples.
minimum derivative index (sample): index of the minimum derivative.
maximum derivative (V): Most positive difference between two samples.
maximum derivative index (sample): index of the maximum derivative.
maximum (V): Maximum minus minimum for the entire trace.
integral (V ms): Integral of the trace.
variance (V²): Variance of the entire trace.
In addition, some parameters are calculated in the way that CAT does. These parameters differ in the following:
onset (ms): Start of the pulse, found from when the trace is above 3 times the baseline RMS noise.
rise time (ms): Calculated from 10% to 90% of the pulse height (and indendent of offset).
decay time (ms): Calculated from 90% to 10% of the pulse height (and indendent of offset).
- Parameters:
dt_us (int, optional) – The microsecond time base of the recording. If provided, relevant output (e.g. rise time) will be in units of seconds. If not provided, these will be in terms of samples.
peak_loc (tuple, float, int, optional) – Location to search for, or used as, the peak. If a tuple of floats, this is the fraction of the record length in which the peak is searched, e.g. a tuple of
(0, 1/2)searches the first half of the trace, while(0, 1)searches the whole trace. If a float, the peak is always assumed to be at that fraction of the record length, e.g.1/4will take the pulse maximum to be at one quarter of the record length. If an integer, this is the location of the peak in samples. Defaults to(1/5, 2/5).bcs (dict) – Keyword arguments for
cait.versatile.BoxCarSmoothing. See its docstring for details.fbl (dict) – Keyword arguments for
cait.versatile.FitBaseline. See its docstring for details.
- Returns:
Main parameters as described above
- Type:
Tuple[np.ndarray]
import cait.versatile as vai events = vai.MockData().get_event_iterator() f = vai.MainParameters(dt_us=events.dt_us) # Preview the working of the calculation vai.Preview(events, f) # Apply function to all events (this returns a tuple of arrays) mp = vai.apply(f, events) # Generate a directory where the keys correspond to the names # of the main parameters and the values to the calculated values mp_dict = {k: v for k, v in zip(f.names(), mp)}
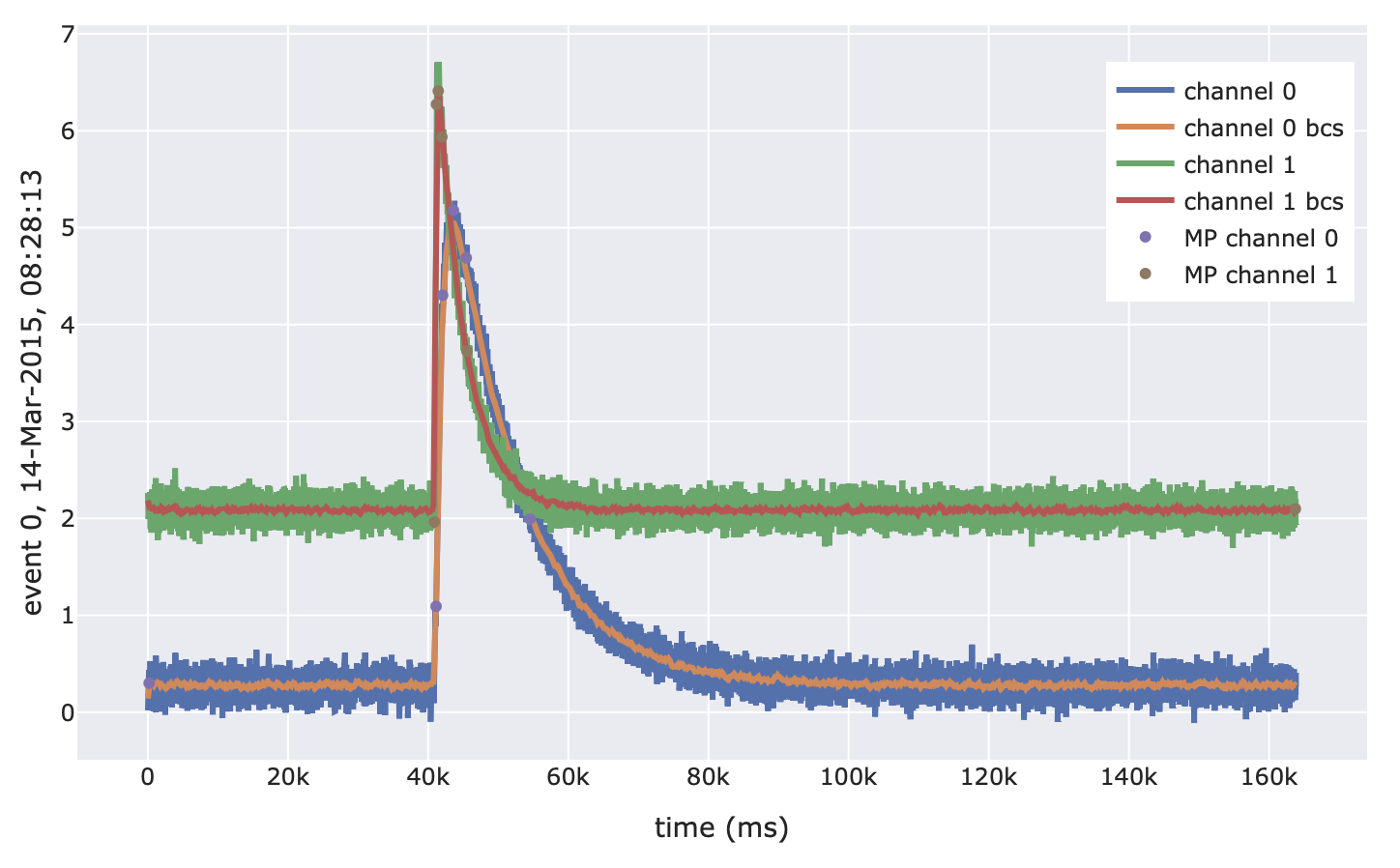
- class cait.versatile.CalcMP(dt_us: int = None, peak_bounds: tuple = (0.2, 0.4), edge_size: float = 0.125, box_car_smoothing: dict = {'length': 50}, fit_baseline: dict = {'model': 0, 'where': 0.125, 'xdata': None})[source]
Calculates (traditional) main parameters for an event.
Warning
Using
cait.versatile.MainParametersis preferred! This function is only kept for legacy reasons.If the argument
dTis set toNone, the output is an array of shape(n_channels, 9), where the nine entries areph, t_0, t_rise, t_max, t_decaystart, t_half, t_end, offset, lin_drift, and quantities starting witht_are given as sample indices. If the argumentdTis set (to the microsecond time base of the recording), the (human readable) quantitiespulse_height (V), onset (ms), rise_time (ms), decay_time (ms), slope (V)as a tuple. Also works for multiple channels simultaneously.- Parameters:
dt_us (int, optional) – The microsecond time base of the recording. If not provided, physical time constants cannot be computed and the function outputs indices. See above.
peak_bounds (tuple, optional) – The region in the record window which is considered for peak search. A tuple
(0,1)searches the entire window,(0,1/2)only searches the first half, etc. Defaults to(1/5, 2/5).edge_size (float, optional) – The (relative) size of the record window that is used to compute the linear drift. Defaults to 1/8, meaning that the first and last 1/8th of the record window is used.
box_car_smoothing (dict, optional) – Arguments for
BoxCarSmoothing, which are used for the application of the moving average. Defaults to{'length': 50}.fit_baseline (dict, optional) – Arguments for
FitBaseline, which are used for the baseline subtractions. Defaults to{'model': 0, 'where': 1/8, 'xdata': None}.
- Returns:
Either an array or tuple. See above.
- Return type:
np.ndarray, tuple
Example:
import cait.versatile as vai # Get events from mock data (and remove baseline) it = vai.MockData().get_event_iterator().with_processing(vai.RemoveBaseline()) # Without the 'dt_us' keyword (output is numpy array) mp_array = vai.apply(vai.CalcMP(), it) # WITH the 'dt_us' keyword (output is tuple with physical values) pulse_height, onset, rise_time, decay_time, slope = vai.apply(vai.CalcMP(dt_us=it.dt_us), it) # Example for plotting a histogram of the pulse hights of both channels vai.Histogram({'ch0': pulse_height[:,0], 'ch1': pulse_height[:,1]})
Example Preview:
import cait.versatile as vai # Get events from mock data (and remove baseline) it = vai.MockData().get_event_iterator().with_processing(vai.RemoveBaseline())[0] # View main parameter calculation in action. The plot shows the original # event, the event after the moving average, and the selected datapoints # for calculating the main parameters. vai.Preview(it, vai.CalcMP())
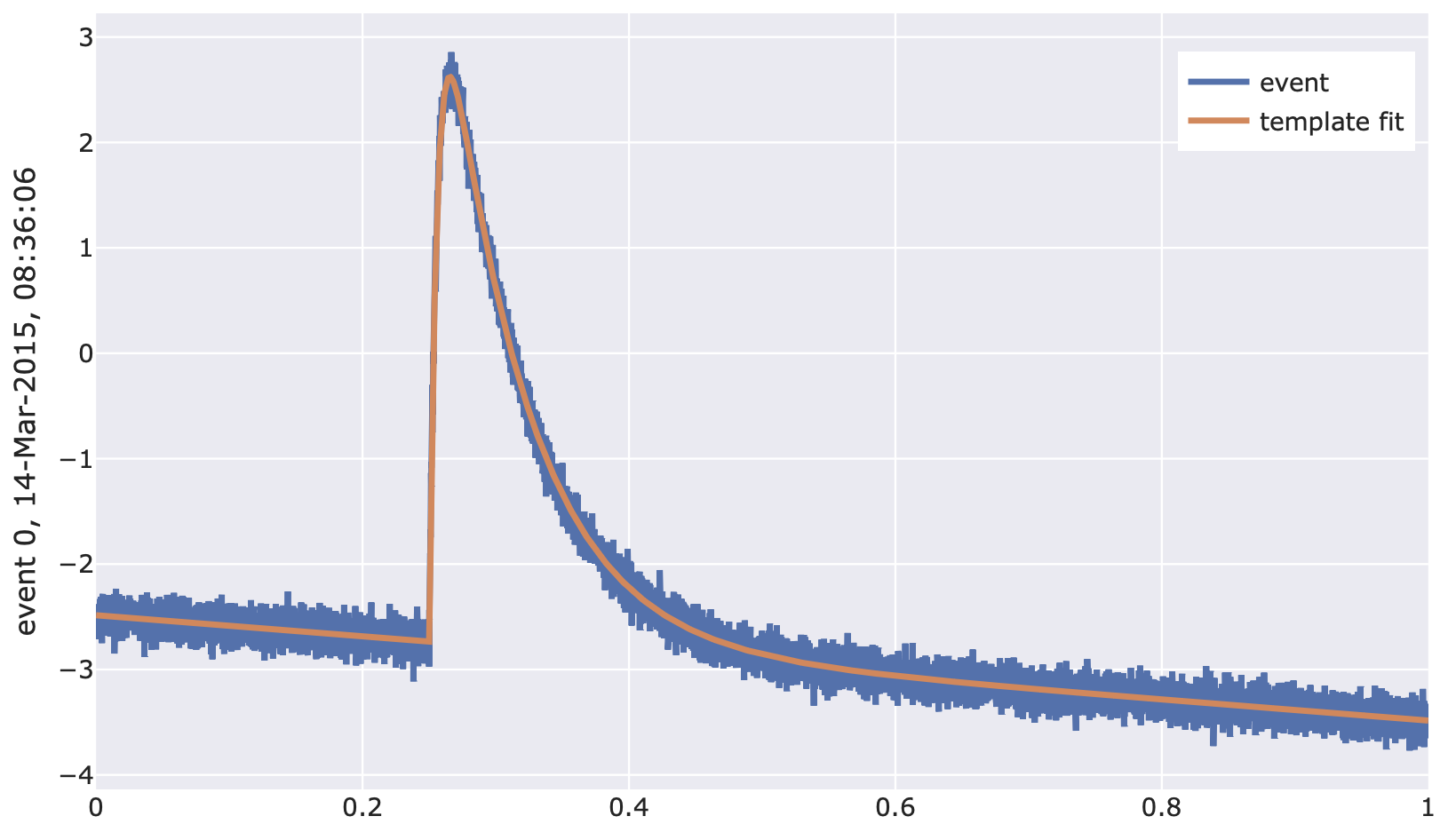
- class cait.versatile.TemplateFit(sev: ndarray, bl_poly_order: int = 0, truncation_limit: float = None, xdata: List[float] = None, fit_onset: bool = True, max_shift: int = 50)[source]
Perform a template fit for single-channel data, i.e. fit a numeric SEV to data with possibility to also specify a polynomial baseline model and a truncation limit. See https://edoc.ub.uni-muenchen.de/23762/ for details.
- Parameters:
sev (np.ndarray) – The template (SEV) to use in the fit.
bl_poly_order (int) – The baseline model to use in the fit. Has to be a non-zero integer or None. If 0, a constant offset is fitted, if 1, a linear baseline is assumed, etc. If None, the baseline is assumed to be constantly 0 (here, it’s the users responsibility to remove the baseline accordingly), defaults to 0, i.e. fitting a constant offset.
truncation_limit (float) – If not None, a truncated fit is performed: all samples between the first and the last sample above ‘truncation_limit’ are ignored in the fit. To determine these samples, the baseline of the event is removed by fitting a polynomial of order ‘bl_poly_order’ to the beginning of the record window. Defaults to None, i.e. not performing a truncated fit.
xdata (np.ndarray) – The x-data array used to evaluate the baseline model. If None, the default
xdata=np.linspace(0, 1, len(sev))is used, defaults to None.fit_onset (bool) – If True, the onset value is fitted. If False, the event is fitted as is, defaults to True
max_shift (int) – The maximum shift value (in samples) to search for a minimum. The onset fit will search the minimum for shifts in
(-max_shift, +max_shift).
- Returns:
Tuple of fit result, optimal shift, and RMS value
([amplitude, constant_bl_coeff, linear_bl_coeff, ...], shift, rms). If you setfit_onset=False, theshiftvalue will just be 0. If the fit fails, all fit parameters are set to 0 and the RMS value is set to -404.- Return type:
Tuple[np.ndarray, int, float]
Example:
import numpy as np import cait.versatile as vai # Get events and SEV from mock data (and select first channel) # Also add an artificial falling baseline to the events md = vai.MockData() it = md.get_event_iterator()[0].with_processing(lambda x: x-np.linspace(0, 1, len(x))) sev = md.sev[0] # Specify fit f = vai.TemplateFit(sev=sev, bl_poly_order=1) # Preview the working of the fit vai.Preview(it, f) # Fit all events in iterator fitpar, opt_shift, rms = vai.apply(f, it) # Plot fit amplitudes vai.Histogram(fitpar[:, 0])
- class cait.versatile.OFPulseHeight(of: ndarray, sev: ndarray, *, filter_groups: List[int | Tuple[int]] = None, max_search: List[int | float | Tuple[int | float]] = (0.2, 0.4), relative_to: List[int] = None, peak_rms_width: int = 5, **kwargs)[source]
Calculate optimum filter pulse heights.
For single channels, this merely filters event traces and performs a maximum search in a specified range of the record window (or evaluates the trace at a specific index). For multiple channels, however, the maximum search (or index evaluation) can be performed relative to other channels.
2D optimum filtering is also supported.
- Parameters:
of (np.ndarray) – The optimum filter(s) to use. One for each channel, i.e. has shape
(N, M//2+1)whereNis the number of channels andMis the record length. Using 2D filters is no exception here: The filters have to be supplied as shape(N, M//2+1)arrays.sev (np.ndarray) – The standard events corresponding to the filters. They are used as reference to calculate the filter (peak) RMS. One standard event per entry in
ofis needed. I.e. has to be of shape(N, M).filter_groups (List[Union[int, Tuple[int]]], optional) – Only relevant if you intend to use 2D filtering. Here, you may specify which filters/channels should be filtered together (producing one output trace). Has to be a list of integers (specifying channels that should be filtered with the regular 1D filter) and tuples of integers (specifying channels that should be filtered together using the 2D filter). E.g. the argument
[(0, 1), 2]would apply the 2D filter to channels 0 and 1 together, and the 1D filter to channel 2. You may only specify each channel exactly once. Defaults to None, i.e. all channels are treated independently and no 2D optimum filtering is applied.max_search (List[Union[int, float, Tuple[Union[int, float]]]], optional) – A list (one entry for each channel, or channel group in case you use a 2D filter) that specifies where to evaluate the filtered trace or where to look for maxima (potentially relative to another channel). If the entry is an integer
k, the filtered trace is evaluated at that integerk. If the entry is a tuple of integers(a, b), the maximum is searched in the interval(a, b). If the entry is a tuple of floats(x, y), the maximum is searched in the interval(record_length*x, record_length*y), i.e. a float tuple specifies the search range relative to the record window. If the entry inrelative_toof the respective channel isNone, the evaluation atk, or search in(a, b)/(x, y)are absolute, i.e. relative to the full record window. If the entry inrelative_tospecifies another channel, the evaluation is done relative to the evaluation position of that channel. E.g. if channel 0 is evaluated at sampler(either because the user specified evaluation atror because the maximum was found atr) and channel 1’srelative_tois channel 0 and itsmax_searchis -10, then the filtered trace of channel 1 is evaluated 10 samples before the evaluation position of channel 0. Defaults to None, i.e. all evaluations are global. Defaults to(0.2, 0.4), i.e. searching between 20% and 40% of the record window for all channels.relative_to (List[int], optional) – Together with
max_search, you can specify relations between the filter evaluations of different channels. Has to be a list (one entry for each channel, or channel group in case you use a 2D filter). ForNoneentries, the respective channel will have its maxima searched (or evaluated) globally (relative to the full record window) according to the respective entry inmax_search. If it is an integerc, the evaluation is performed relative to the evaluation index of channelc. This evaluation index can either result from a fixed evaluation position (specified inmax_search) or an actual maximum search. Defaults toNone, i.e. independent evaluation for all channels.peak_rms_width (int, optional) – The number of samples before and after the filter evaluation sample that are used for calculating the filter RMS value. Defaults to 5 samples
kwargs (Any) – Additional keyword arguments for
cait.versatile.OptimumFiltering(orcait.versatile.OptimumFiltering2D). Most notably, you can setmethod='linear'for a linear convolution of event traces larger than the one dictated bysev.
- Returns:
Tuple of calculated values. See
vai.OFPulseHeight.names()andvai.OFPulseHeight.dtypesfor what they are and which data types they have. Their description is given below.- Return type:
Tuple[Union[float, int]]
Output parameters are:
of_ph (V): The ‘optimum filter pulse height’. Either evaluated at a fixed sample or through the maximum search in a specified interval (see arguments
max_searchandrelative_to). Note that this is not necessarily the global maximum of the filtered event.of_max_val (V): The global maximum of the filtered event.
of_eval_pos (samples): The position (index) where the filtered event was evaluated (the value of the filtered event at this index is of_ph).
of_max_pos (samples): The position (index) of the global maximum of the filtered event (the value of the filtered event at this index is of_max_val).
of_rms (V): The root mean square (RMS) value between the filtered event and the filtered reference SEV. The reference is obtained by scaling the SEV to of_ph and shifting it relative to the event such that their of_eval_pos indices are aligned. This RMS value is global (all samples which were not invalidated because of the shifting).
of_peak_rms (V): Same as of_rms but only the number of samples specified by argument
peak_rms_widthbefore and after the of_eval_pos is used for the calculation.
Warning
If you directly use this function, make sure to retrieve its results by first applying it to an iterator
of_res = vai.apply(f, it)and unpacking it into a dictionaryof_res_dict = {k: v for k, v in zip(f.names(), of_res)}(as explained in the example below). By doing so, you future-proof your code as more outputs might be added to the function in the future.Example:
import cait.versatile as vai record_length = 2**14 # Generate mock data (two channels) md = vai.MockData(record_length=record_length) it = md.get_event_iterator() sev, of = md.sev, md.of # Filtering single channel f1 = vai.OFPulseHeight( of=of[0], sev=sev[0], ) # See what the function is doing vai.Preview(it[0], f1) # Apply function to all events (this returns a tuple of arrays). of_res = vai.apply(f1, it[0]) # Generate a directory where the keys correspond to the names # of the function outputs and the values to the calculated values. # Always (!) access them like this as the number of output values # might increase in the future. By accessing them like this, you make # sure that your code doesn't break. of_res_dict = {k: v for k, v in zip(f1.names(), of_res)}
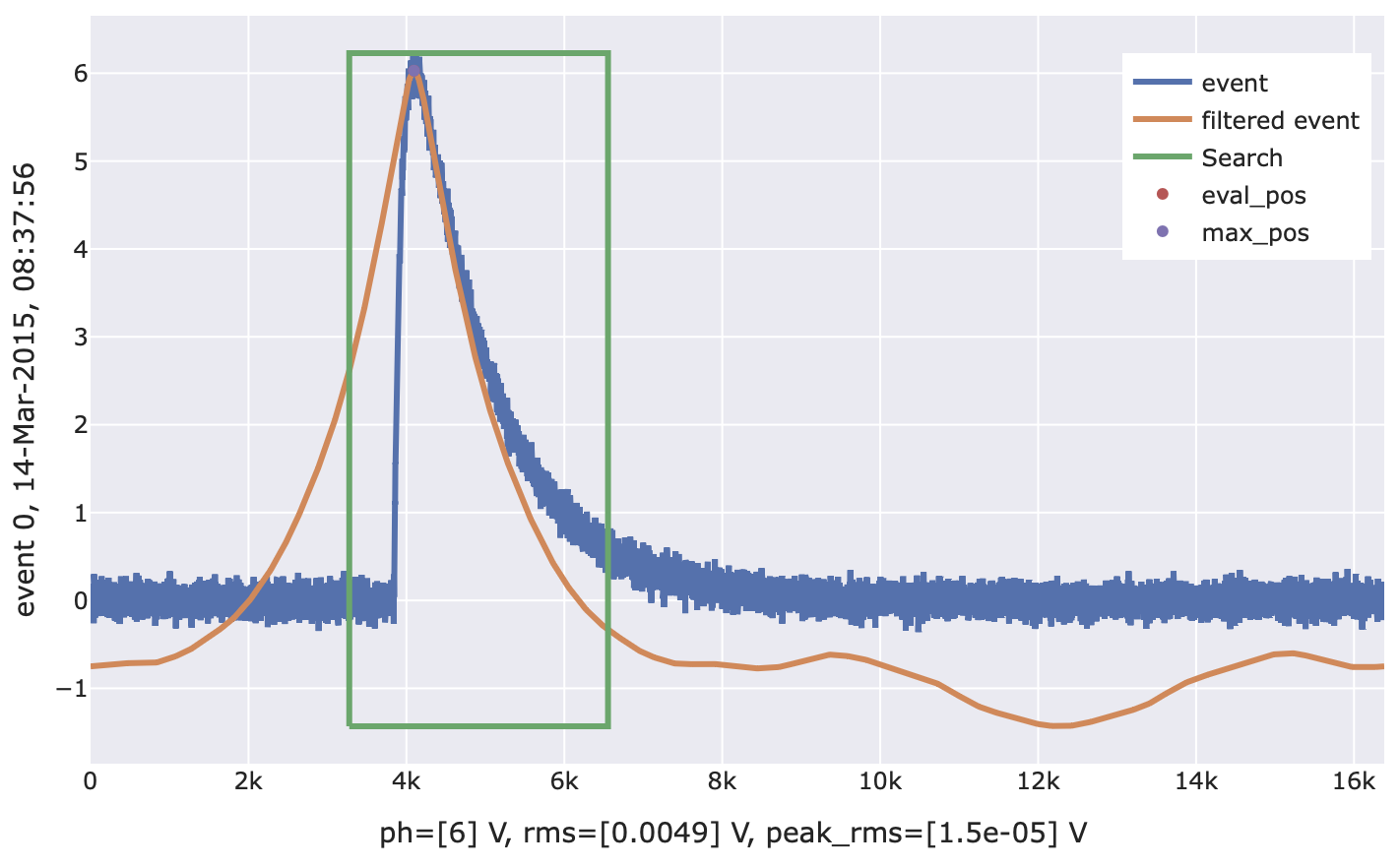
# Filtering two channels and perform a maximum search for # the second one in an interval [-300, -100] samples relative # to the maximum found for the first channel. f2 = vai.OFPulseHeight( of=of, sev=sev, relative_to=[None, 0], max_search=[(0.2, 0.4), (-300, -100)], ) vai.Preview(it, f2)
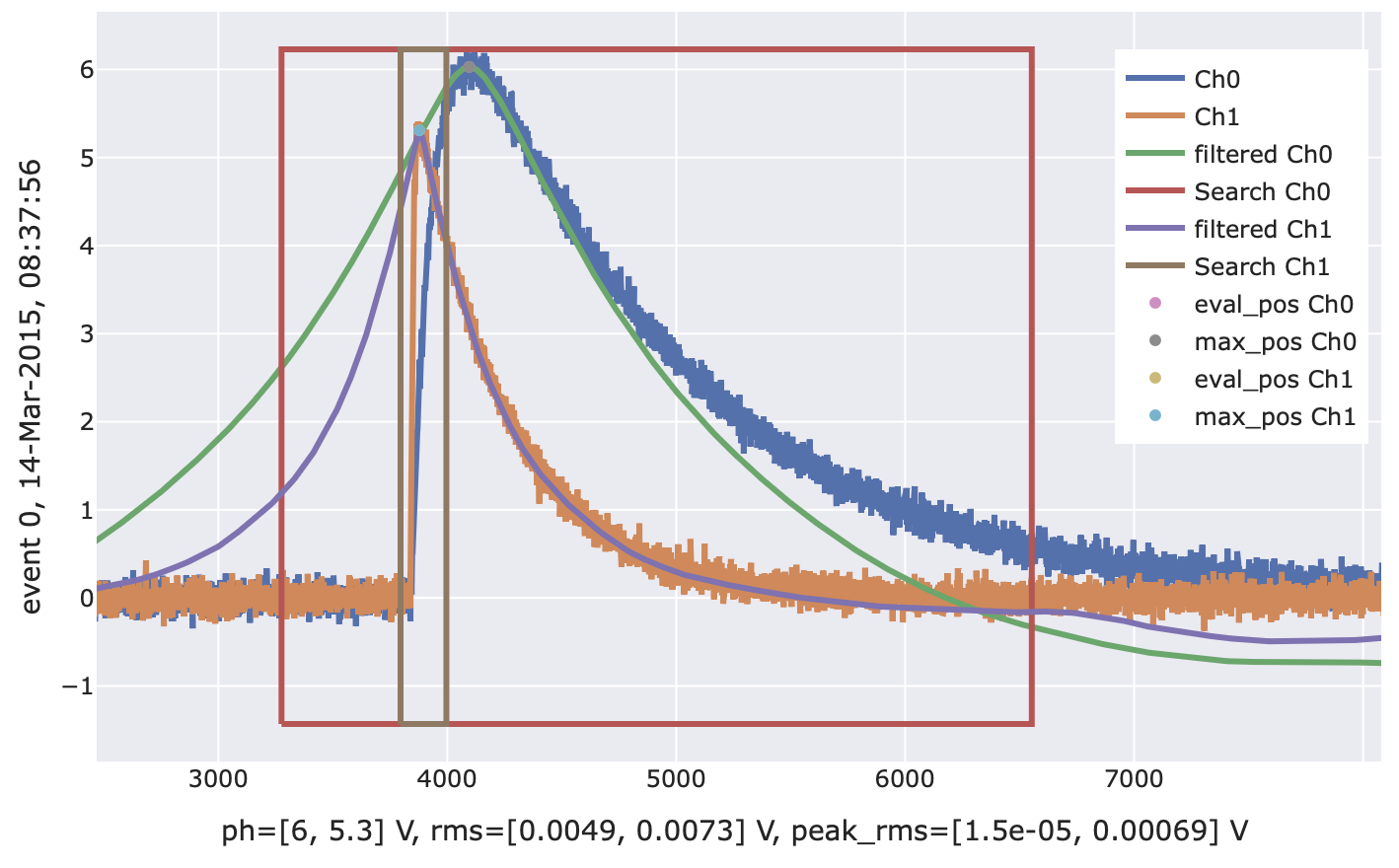
# Generate mock stream data with three channels s = vai.MockStream( rate_Hz=1, seed=137, pulse_shape=[[0.5, 0.5, 0.3, 0.1, 10.0], [0.3, 0.5, 0.3, 0.01, 4.0], [0.3, 0.5, 0.3, 0.01, 4.0]], tp_shape=[[0.5, 0.5, 0.3, 0.01, 20.0], [0.5, 0.5, 0.3, 0.01, 10.0], [0.5, 0.5, 0.3, 0.01, 10.0]], baseline_sig=[0.005, 0.001, 0.002], ) it = s.get_event_iterator( ["Ch0", "Ch1", "Ch2"], record_length=record_length, inds=[(4+x)*record_length for x in range(10)], ) # Filter two of the three channels with larger stream window # (potentially reduces filter edge effects). f3 = vai.OFPulseHeight( of=of, sev=sev, method="linear", ) vai.Preview(it[:2].with_extended_window(), f3)
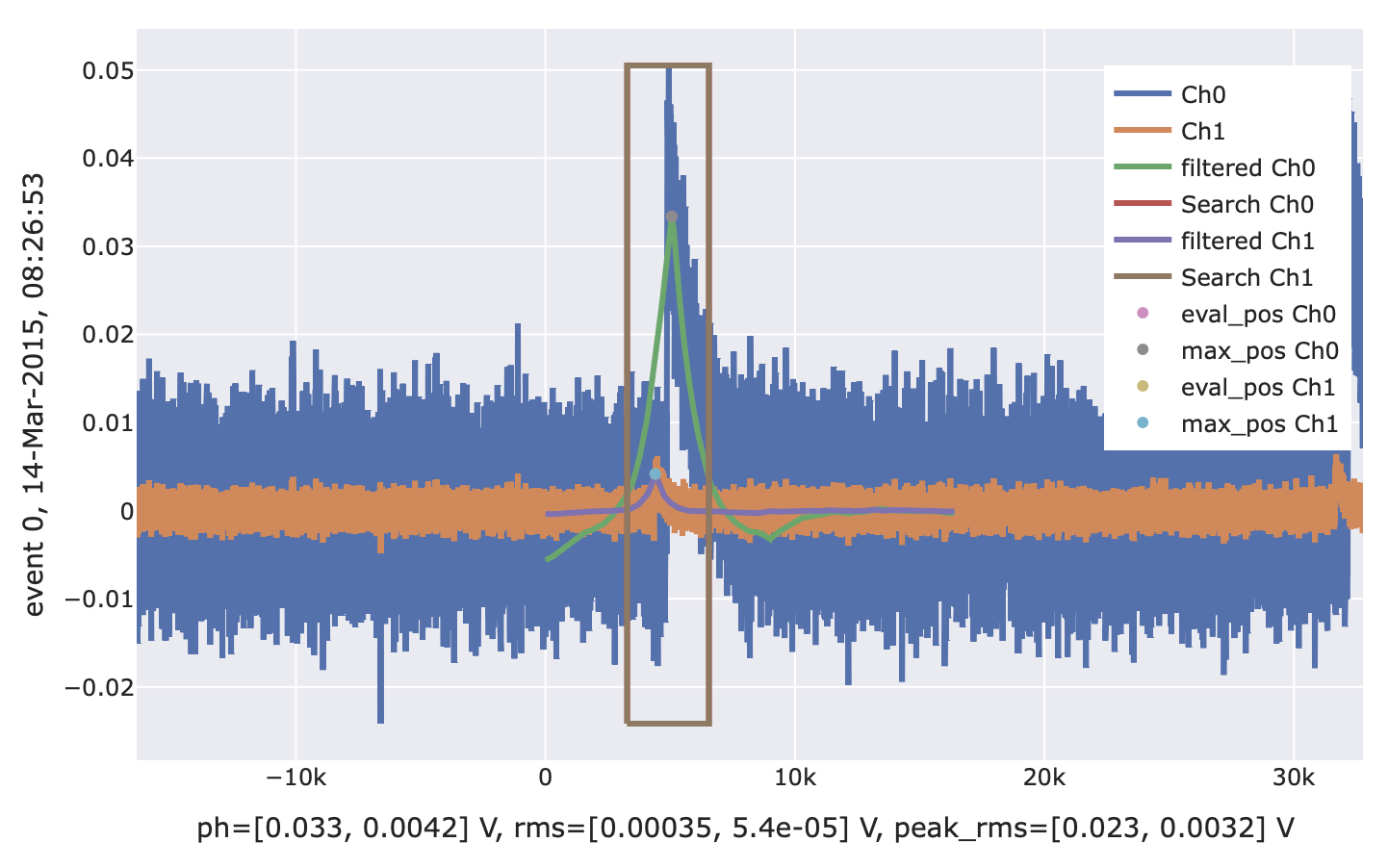
# Filter first two channels with 2D filter and read third one # relative to the evaluation position of the 2D filtered trace. # Note that here, we just use the filter/sev of the second channel # twice. This is just for this demonstration (you would have # three different filters/templates of course). f4 = vai.OFPulseHeight( of=[of[0], of[1], of[1]], sev=[sev[0], sev[1], sev[1]], filter_groups=[(0, 1), 2], # 0 and 1 together, 2 separately relative_to=[None, 0], # (0, 1) absolute, 2 relative to (0, 1) max_search=[(0., 1.), -1200], # maximum search in entire window for (0, 1), # fixed evaluation of 2 (1200 samples before # maximum of (0, 1)). ) vai.Preview(it, f4)
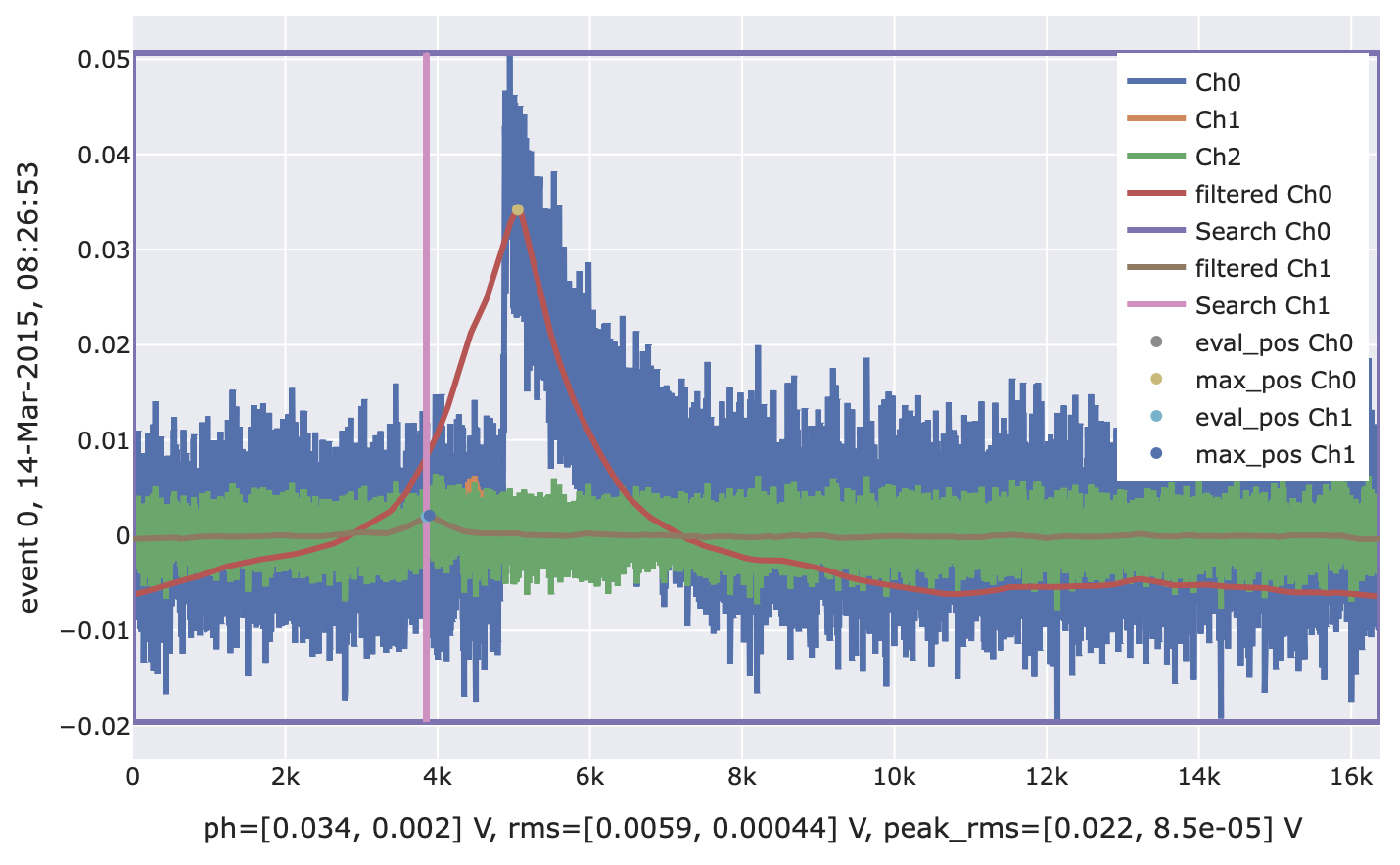
Perform a correlated template fit for multi-channel data, i.e. fit a numeric SEV to data with possibility to also specify a polynomial baseline model (for each channel individually) and a truncation limit (for each channel individually). The ‘correlated’ in this context means that you can choose which of the channel’s onset should be fitted (possibly multiple, see below). See https://edoc.ub.uni-muenchen.de/23762/ and https://mediatum.ub.tum.de/?id=1294132 for details.
- Parameters:
sev (np.ndarray) – The template (SEV) to use in the fit (at least two channels).
bl_poly_order (List[int]) – List of the baseline models to use in the fit (one entry for each channel). Has to be a non-zero integer or None. If 0, a constant offset is fitted, if 1, a linear baseline is assumed, etc. If None, the baseline is assumed to be constantly 0 (here, it’s the users responsibility to remove the baseline accordingly), defaults to 0, i.e. fitting a constant offset for all channels.
truncation_limit (List[float]) – List with as many entries as there are channels. For each entry that is not None, a truncated fit is performed: all samples between the first and the last sample above ‘truncation_limit’ are ignored in the fit. To determine these samples, the baseline of the event is removed by fitting a polynomial of order ‘bl_poly_order’ to the beginning of the record window. Defaults to None, i.e. not performing a truncated fit in any channel.
xdata (np.ndarray) – The x-data array used to evaluate the baseline model (1-dimensional). If None, the default
xdata=np.linspace(0, 1, sev.shape[-1])is used, defaults to None.fit_onset (List[bool]) – List with as many entries as there are channels. For each entry that is True, the onset value of the respective channel is fitted. If False, the channel does not participate in the onset fit. If only one of the entries is True, this channel is the ‘dominant’ one, i.e. its onset is fitted and all other channels are moved (passively) in unison. If multiple are True, their chi-squared for the fit is combined, i.e. the template is still moved in unison, but the minimizer considers all channels. Defaults to True, i.e. fit onset in all channels
max_shift (int) – The maximum shift value (in samples) to search for a minimum. The onset fit will search the minimum for shifts in
(-max_shift, +max_shift).
- Returns:
Tuple of fit result, optimal shift, and RMS value
([[amplitude_ch0, constant_bl_coeff_ch0, linear_bl_coeff_ch0, ...], [amplitude_ch1, constant_bl_coeff_ch1, linear_bl_coeff_ch1, ...]], shift, [rms_ch0, rms_ch1, ...]). If you setfit_onset=False, theshiftvalue will just be 0. If the fit fails, all fit parameters are set to 0 and the RMS value is set to -404. If different orders of baseline polynomials are used for different channels, the output is extended to the largest used polynomial order (i.e. unused coefficients are 0).- Return type:
Tuple[np.ndarray, int, np.ndarray]
Example:
import numpy as np import cait.versatile as vai # Get events and SEV from mock data (and select first channel) # Also add an artificial falling baseline to the events md = vai.MockData() it = md.get_event_iterator().with_processing(lambda x: x-np.linspace(0, 1, x.shape[-1])) sev = md.sev # Specify fit f = vai.TemplateFitCorrelated(sev=sev, bl_poly_order=[1, 3], fit_onset=[True, False]) # Preview the working of the fit vai.Preview(it, f) # Fit all events in iterator fitpar, opt_shift, rms = vai.apply(f, it) # Plot fit amplitudes vai.Histogram({"channel 0": fitpar[:, 0, 0], "channel 1": fitpar[:, 1, 0]}, xlabel="Pulse Height")
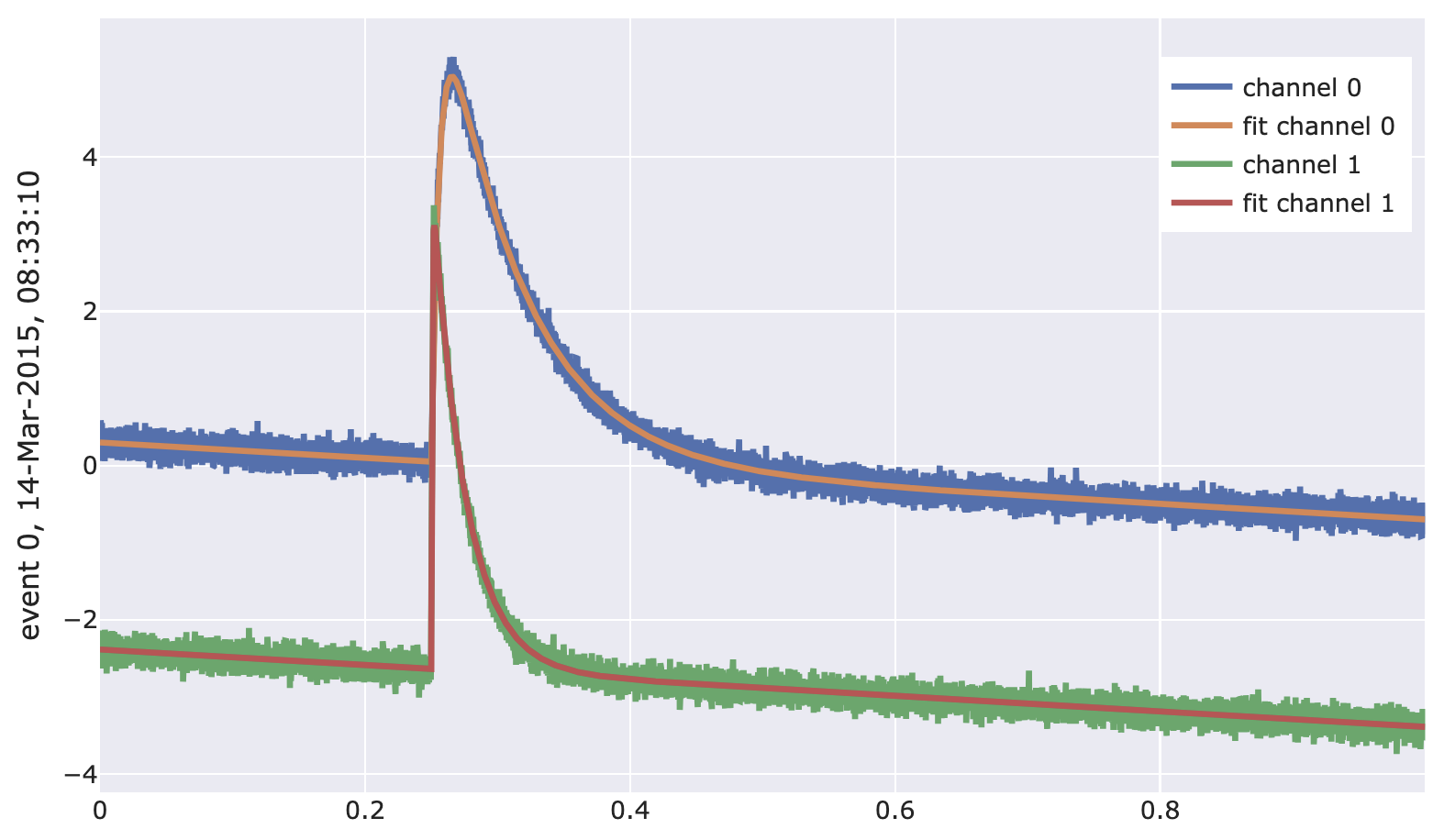
- class cait.versatile.TemplateFit_FQLC(sev: ndarray, bl_poly_order: int = None, truncation_limit: float = None, xdata: List[float] = None, fit_onset: bool = True, max_shift: int = 50, fqlc_method: str = 'mmd', fql_voltage: float = None, fqlc_thresh: float = None, true_pulseheight: float = None, pileup_trigger_rms: float = 8, pileup_trigger_window_size: int | float = 0.05, pileup_buffer_samples: int = 50)[source]
This class extends
cait.versatile.TemplateFit. Perform a template fit for single-channel data, i.e. fit a numeric SEV to data and additionally allow for correction of flux quantum losses (FQLs) and for auto-detection of post-pulse-pileups, excluding pileup-affected parts of the voltage trace from the fit.- Parameters:
sev (np.ndarray) – The template (SEV) to use in the fit.
bl_poly_order (int) – The baseline model to use in the fit. Has to be a non-zero integer or None. If 0, a constant offset is fitted, if 1, a linear baseline is assumed, etc. As a constant baseline is always removed before the fit in the process of flux quantum loss correction, setting bl_poly_order to None is effectively the same as setting it to 0. Defaults to None.
truncation_limit (float) – If not None, a truncated fit is performed: all samples between the first and the last sample above ‘truncation_limit’ are ignored in the fit. To determine these samples, the baseline of the event is removed by fitting a polynomial of order ‘bl_poly_order’ to the beginning of the record window. Defaults to None, i.e. not performing a truncated fit.
xdata (np.ndarray) – The x-data array used to evaluate the baseline model. If None, the default
xdata=np.linspace(0, 1, len(sev))is used, defaults to None.fit_onset (bool) – If True, the onset value is fitted. If False, the event is fitted as is, defaults to True
max_shift (int) – The maximum shift value (in samples) to search for a minimum. The onset fit will search the minimum for shifts in
(-max_shift, +max_shift).fqlc_method (str) – One of three methods for the flux quantum loss (FQL) correction that is applied before the calculation of the saturation time: “mmd”, “slope” or “true_ph”. “mmd” (mininmum-minimum difference) calculates the FQL as difference between the minima before and after the pulse (with some fluctuation mitigation). “slope” calculates the FQL as the slope of the event. “true_ph” assumes that the true pulse height (without FQL) is known - and provided in the parameter true_pulseheight - and calculates the FQL as the difference between true and apparent pulse height. Defaults to the recommended “mmd”.
fql_voltage (float, optional) – If the voltage drop of an FQL is known and provided here, the correction shift will be an integer multiple of this value, instead of any value. In this case, the number of FQ lost is determined by subtracting the threshold (param “fqlc_thresh”) from the calculated shift and then rounding up to an integer multiple of fql_voltage. Defaults to None.
fqlc_thresh (float, optional) – Minimum shift value to accept as FQL and correct for. Smaller or negative values are assumed to not stem from FQLs. If no value is given, fqlc_thresh defaults to one third of fql_voltage. If no value is given for fql_voltage either, fqlc_thresh defaults to 0.2 V.
true_pulseheight (float, optional) – The known true pulse height as defined by the maximum possible pulse height for fully saturated pulses. Necessary for fqlc_method “true_ph”. Defaults to None.
pileup_trigger_rms (float) – The threshold (in sigmas) for a moving z-score trigger to find pileup pulses. All samples after the start of a pileup are disregarded for the fit, starting pileup_buffer_samples before the sample that triggers. If None, no pileup detection is carried out. Defaults to 8.
pileup_trigger_window_size (Union[int, float], optional) – The size of the sliding window for the pileup-finding z-score trigger. If it’s an integer, this will be the number of samples in the window, if it’s a float, the number will be scaled to the record_length of the events (e.g. if 1/20, the window will be 1/20th of the record_length). The larger the window, the more robust the trigger is. Defaults to 1/20.
pileup_buffer_samples (int) – Number of samples to exclude from the fit before the first pileup trigger (the pileup pulse typically starts a bit earlier than it is above the trigger threshold). Thus all, samples after the triggering sample minus pileup_buffer_samples are excluded. Defaults to 50.
- Returns:
Tuple of fit result, optimal shift, RMS value and a flag indicating whether the result should be discarded due to problems in the fitting procedure
([amplitude, constant_bl_coeff, linear_bl_coeff, ...], shift, rms). If you setfit_onset=False, theshiftvalue will just be 0. If the fit fails, the discard flag is set to True.- Return type:
Tuple[np.ndarray, int, float, bool]
Example:
import numpy as np import cait.versatile as vai # Get events and SEV from mock data (and select first channel) md = vai.MockData() sev = md.sev[0] events = md.get_event_iterator()[0].with_processing(vai.RemoveBaseline()) # Define a function that (roughly) mimics events with FQL. # (This is of course only needed to make this example # self-contained. You would have actual data for such events.) SHIFT = 3 def mock_fql(event): fake_event = event.copy() ph = np.max(fake_event) flag = fake_event > ph - SHIFT fake_event[flag] = ph - SHIFT k = np.argmax(flag[::-1]) fake_event[-k:] += ph*sev[-k:]/np.max(sev[-k:]) - vai.BoxCarSmoothing()(fake_event)[-k:] - SHIFT return fake_event # Add this function as processing (to fake FQL events). # Again, you don't need this because you have FQL data. events = events.with_processing(mock_fql) # The template fit function f = vai.TemplateFit_FQLC(sev, truncation_limit=SHIFT) # Preview the working of the FQL corrected TemplateFit vai.Preview(events, f) # Or calculate the fit values. # Make sure to use the 'discard' flag to exclude invalid results! fitpars, shift, rms, discard = vai.apply(f, events) # Check the distribution of pulse heights vai.Histogram(fitpars[~discard])
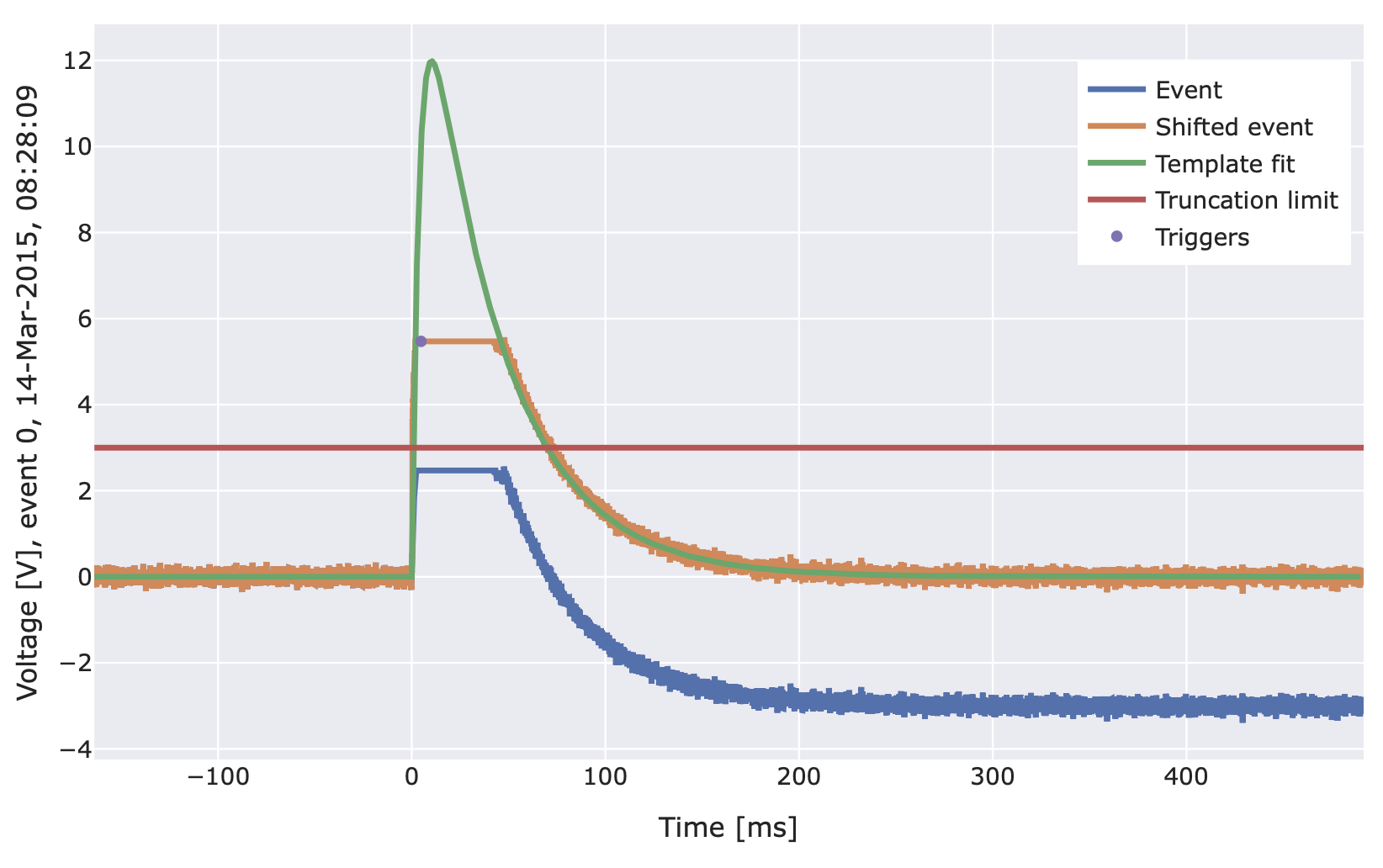
- class cait.versatile.SaturationTime(saturation_level_mode: str = 'relative', saturation_level: float = 0.9, smoothing_length: int = None, peak_bounds: tuple = (0.23, 0.29), fqlc_method: str = 'mmd', fql_voltage: float = None, fqlc_thresh: float = None, true_pulseheight: float = None)[source]
Calculates the saturation time for a pulse (one channel), given by the time that the pulse spends above the saturation level, calculated around the pulse maximum. The point in time where the pulse falling flank of the pulse dips below the saturation level is calculated after moving-average smoothing, if the parameter “smoothing_length” is set to a positive (integer) value, while the corresponding value for the rising edge is always calculated without smoothing, due to the rise typically being much faster than the decay. If the pulse does not fall below the saturation level before and/or after its maximum, a saturation time of -1 is returned as a flag that reconstruction did not work, while keeping the float nature of the return values for a smoother workflow.
- Parameters:
saturation_level_mode – The mode defining how the saturation level given in the parameter saturation_level is interpreted. Passing “relative” interprets the saturation_level relative to the ph of the considered pulse (e.g. saturation_level=0.9 to calculate the time that the pulse is above 90% of its pulse height). Passing “absolute” interprets the saturation_level as an absolute voltage value. Defaults to “relative”.
saturation_level (float) – The saturation level, either relative to the pulse height of the considered event, or as an absolute voltage value, as defined by the parameter saturation_level_mode. Defaults to 0.9.
smoothing_length (int) – Length of the moving average (box-car-) smoothing to be applied before finding the moment where the pulse decays below the saturation level. Defaults to None.
peak_bounds (tuple) – Peak bounds, relative to the record window, for the calculation of main parameters, defining where the maximum of the pulse can be found. The saturation time will be calculated around this maximum, so the choice of peak bounds can exclude pileups or SQUID resets. Defaults to (0.23, 0.29).
fqlc_method (str) – One of three methods for the flux quantum loss (FQL) correction that is applied before the calculation of the saturation time: “mmd”, “slope” or “true_ph”. “mmd” (mininmum-minimum difference) calculates the FQL as difference between the minima before and after the pulse (with some fluctuation mitigation). “slope” calculates the FQL as the slope of the event. “true_ph” assumes that the true pulse height (without FQL) is known - and provided in the parameter true_pulseheight - and calculates the FQL as the difference between true and apparent pulse height. Defaults to the recommended “mmd”.
fql_voltage (float, optional) – If the voltage drop of an FQL is known and provided here, the correction shift will be an integer multiple of this value, instead of any value. In this case, the number of FQ lost is determined by subtracting the threshold (param “fqlc_thresh”) from the calculated shift and then rounding up to an integer multiple of fql_voltage. Defaults to None.
fqlc_thresh (float, optional) – Minimum shift value to accept as FQL and correct for. Smaller or negative values are assumed to not stem from FQLs. If no value is given, fqlc_thresh defaults to one third of fql_voltage. If no value is given for fql_voltage either, fqlc_thresh defaults to 0.2 V.
true_pulseheight (float, optional) – The known true pulse height as defined by the maximum possible pulse height for fully saturated pulses. Necessary for fqlc_method “true_ph”. Defaults to None.
- Returns:
Saturation time in ms.
- Return type:
float
Example:
import numpy as np import cait.versatile as vai # Get events and SEV from mock data (and select first channel) md = vai.MockData() sev = md.sev[0] events = md.get_event_iterator()[0].with_processing(vai.RemoveBaseline()) # Define a function that (roughly) mimics events with FQL. # (This is of course only needed to make this example # self-contained. You would have actual data for such events.) SHIFT = 3 def mock_fql(event): fake_event = event.copy() ph = np.max(fake_event) flag = fake_event > ph - SHIFT fake_event[flag] = ph - SHIFT k = np.argmax(flag[::-1]) fake_event[-k:] += ph*sev[-k:]/np.max(sev[-k:]) - vai.BoxCarSmoothing()(fake_event)[-k:] - SHIFT return fake_event # Add this function as processing (to fake FQL events). # Again, you don't need this because you have FQL data. events = events.with_processing(mock_fql) # Preview the working of the SaturationTime calculation vai.Preview(events, vai.SaturationTime()) # Or calculate it for all events. sat_times = vai.apply(vai.SaturationTime(), events) # Check the distribution of saturation time values vai.Histogram(sat_times)
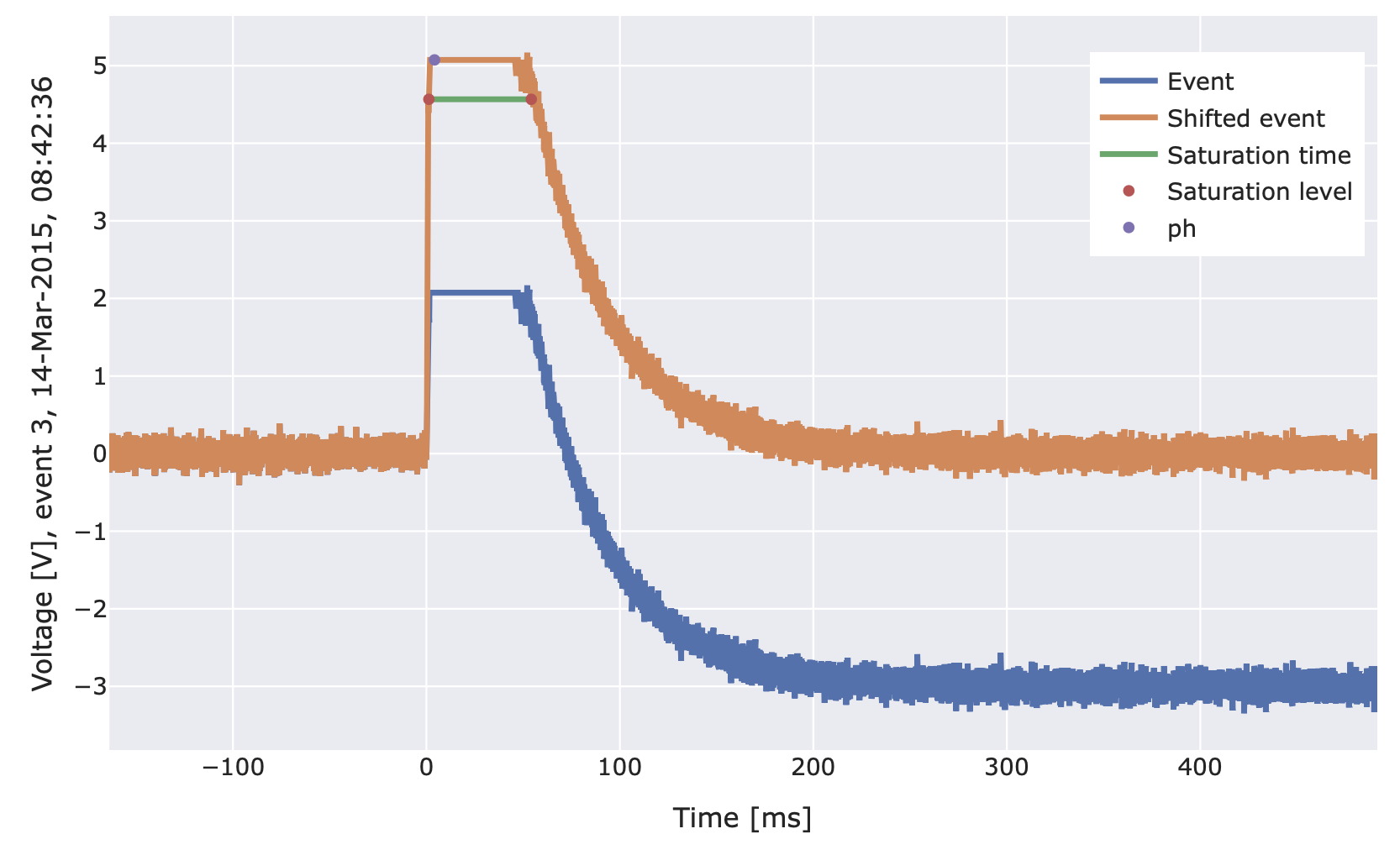
- class cait.versatile.NPeaks(window_size: int | float = 0.05, threshold: float = 3.5)[source]
Determine the number of peaks in an event by applying a moving z-score trigger to the trace.
- Parameters:
window_size (Union[int, float], optional) – The size of the sliding window for the z-score trigger. If it’s an integer, this will be the number of samples in the window, if it’s a float, the number will be scaled to the record_length of the events (e.g. if 1/20, the window will be 1/20th of the record_length). The larger the window, the more robust the trigger is. However, you will miss potential triggers in the beginning of the event because the first sample that can reliably searched after applying the moving z-score is at
window_size. Defaults to 1/20threshold (float, optional) – The threshold (in sigmas) for the trigger, defaults to 3.5
- Returns:
Number of peaks found.
- Return type:
int
Example:
import numpy as np import cait.versatile as vai md = vai.MockData() sev = md.sev[0] it = md.get_event_iterator()[0] def pileup(event): # generate a random pulse height between 0 and 3 height = 3*np.random.rand() # generate a random position for the pulse after the first pulse pos = np.random.randint(md.record_length//8, 3*md.record_length//4) # overlay new event on top of original new_event = event.copy() new_event[pos:] += sev[:(md.record_length-pos)] return new_event vai.Preview(it.with_processing(pileup), vai.NPeaks(window_size=1/20, threshold=5))
- class cait.versatile.TriggerSurvival(trigger_fnc: callable, target_ind: int, tolerance_samples: int = 10)[source]
Function that checks whether or not a given event would have survived triggering.
In the preview, the ‘search_window’-box marks the area which is searched for samples exceeding the threshold. Parts outside the box are not searched because they can in general not be filtered correctly (c. f.
cait.versatile.functions.trigger.triggerbase.trigger_base()). However, if a sample is found above threshold close to the right edge of the box, the maximum search is continued outside.- Parameters:
trigger_fnc (callable) – The trigger function to use. Has to have function signature
f(event: np.ndarray) -> (trigger_inds: list, trigger_vals: list).target_ind (int) – The index on the voltage trace where the event (maximum) was placed, i.e. where the trigger is expected to be found.
tolerance_samples (int) – Maximum number of samples that a trigger can deviate from
target_indsuch that it is still considered a trigger.
- Returns:
Tuple
(did_trigger, trigger_value, trigger_index). If no trigger was found (including tolerance), the tuple(False, 0, 0)is returned.- Return type:
Tuple[bool, float, int]
from functools import partial import scipy as sp import numpy as np import cait.versatile as vai # This example is not very meaningful. Usually, one would # superimpose pulses onto empty baselines and check if they # are triggered. To make this example self-contained, we # use the pulses ov MockData (not empty baselines). md = vai.MockData() rl = md.record_length sev, of = md.sev[0], md.of[0] it = vai.MockData(record_length=6*rl).get_event_iterator()[0] # Make a 'long' version of the SEV to be superimposed padded_sev = np.zeros(6*rl) padded_sev[3*rl:4*rl] = np.array(sev) # Simulate random pulse heights and superimpose traces sim_phs = sp.stats.uniform.rvs(size=len(it)) chunk_iterator = vai.iterators.PulseSimIterator( it, sev=padded_sev, pulse_heights=sim_phs, ) # Trigger function is trigger_of with a given threshold. # If a trigger is found within 10 samples around target_ind # (the maximum of the SEV), the trigger is considered a 'survivor' f = vai.TriggerSurvival( trigger_fnc=partial(vai.trigger_of, of=of, threshold=0.1), target_ind=np.argmax(padded_sev), tolerance_samples=10 ) # Preview vai.Preview(chunk_iterator, f) # Calculate survival for all pulses trigger_flag, trigger_val, trigger_ind = vai.apply(f, chunk_iterator)
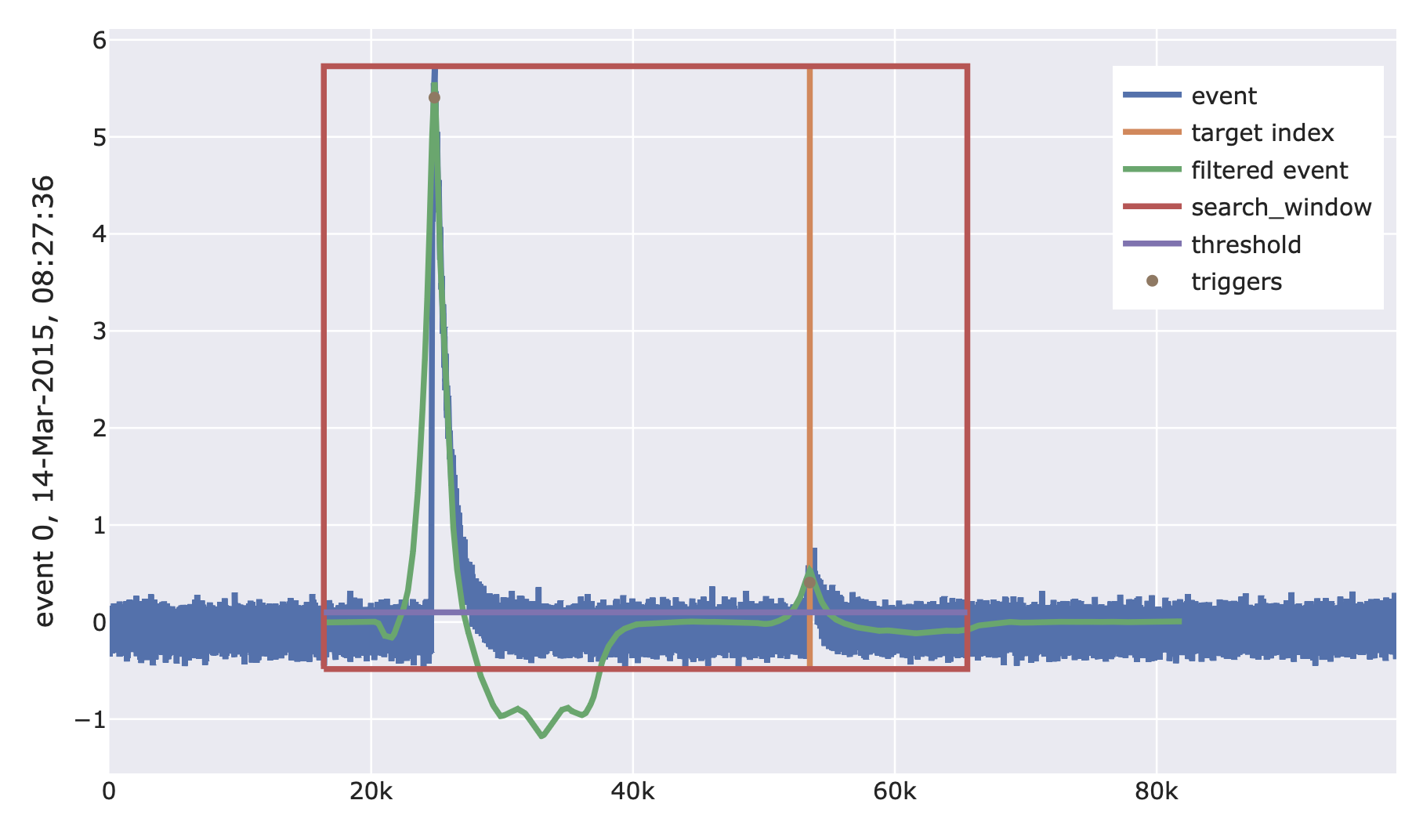
Utility functions
- cait.versatile.apply(f: Callable, ev_iter: IteratorBaseClass, n_processes: int = None, pb_prefix: str = '')[source]
Apply a function to events provided by an EventIterator.
Multiprocessing and resolving batches as returned by the iterator is done automatically. The function returns a numpy array where the first dimension corresponds to the events returned by the iterator. Higher dimensions are as returned by the function that is applied. Batches are resolved, i.e. calls with an
EventIterator(..., batch_size=1)andEventIterator(..., batch_size=100)yield identical results.- Parameters:
f (Callable) – Function to be applied to events.
ev_iter (
IteratorBaseClass) – Events for which the function should be applied.n_processes (int, optional) – Number of processes to use for multiprocessing. If None,
cait._available_workersis used. Defaults to None.pb_prefix (str) – An optional prefix for the progress bar.
- Returns:
Results of
ffor all events inev_iter. Has same structure as output off(just with an additional event dimension).- Return type:
Any
Example:
import cait.versatile as vai import numpy as np def func1(event): return np.max(event) def func2(event): return np.min(event), np.max(event) # Example when func has one output it = vai.MockData().get_event_iterator(batch_size=42) out = vai.apply(func1, it) # Example when func has two outputs it = vai.MockData().get_event_iterator(batch_size=42) out1, out2 = vai.apply(func2, it) # Example using a function defined inline it = vai.MockData().get_event_iterator()[0] out = vai.apply(lambda x: np.max(x), it)
- cait.versatile.timestamp_coincidence(a: List[int], b: List[int], interval: Tuple[int])[source]
Determine the coincidence of timestamps in two separate arrays.
Constructs half-open intervals [a+interval[0], a+interval[1]) around timestamps in a and checks which timestamps in b fall into these intervals.
Note that the timestamps have to be strictly monotonically increasing! However, it is possible that the resulting intervals overlap. In that case, the intervals are symmetrically shrunk to create two smaller intervals which touch in the middle. E.g. if the intervals are [12, 20) and [15, 23), the resulting new intervals will be [12, 18) and [18, 23).
- Parameters:
a (List[int]) – Array of timestamps in microseconds
b (List[int]) – Array of timestamps in microseconds
interval (Tuple[int]) – Tuple of length 2 which specifies how many microseconds before and after a timestamp should be considered to be in coincidence. E.g. (-10,20) means that for the timestamp 100, the interval [90,120) would be considered. Note that also intervals (1,10) and (-10,-5) are valid.
- Returns:
INDICES of b in coincidence with a,
corresponding INDICES of a which elements of b are in coincidence with,
INDICES of b NOT in coincidence with a
- Return type:
Tuple
Example:
a = np.array([10, 20, 30, 40]) b = np.array([1, 11, 35, 42, 45]) inside, coincidence_inds, outside = vai.timestamp_coincidence(a,b,(-1,3)) inside # array([1, 3]) outside # array([0, 2, 4]) coincidence_inds # array([0, 3]) b[inside] # array([11, 42]) = corresponding timestamps b[outside] # array([ 1, 35, 45]) = corresponding timestamps a[coincidence_ind] # array([10, 40])
- cait.versatile.sample_noise(trigger_inds: List[int], record_length: int, n_samples: int = None)[source]
Get stream indices of noise traces. Record windows of length record_length are aligned around trigger_inds (at 1/4th of the record length) and noise indices are only sampled from large enough intervals outside these windows (i.e. only if at least one noise window of length record_length fits within such gaps). Note that the selected noise traces can still contain pulses and artifacts.
- Parameters:
trigger_inds (List[int]) – The indices (not timestamps) of the triggered events. To get as clean noise traces as possible, this should include all triggers, i.e. also testpulses for example.
record_length (int) – The length of the record window in samples. This has to match the record length which was used for obtaining trigger_inds for meaningful results.
n_samples (int, optional) – If specified, a total number of at most n_samples are returned. The actual number of returned noise traces can be lower depending on the available ‘empty space’ between actual triggers.
- Returns:
List of indices for noise traces. The record windows can be recovered by aligning them at
int(record_length/4)aroundindices.- Return type:
List[int]
- cait.versatile.event_building(trigger_ts: List[List[int]], trigger_phs: List[List[float]], record_length: int, dt_us: int, n_passive_ch: int = 0, tp_ts: List[List[int]] = None, tpas: List[List[float]] = None, interval: Tuple[float] = None)[source]
Build events from trigger timestamps (of multiple channels) and exclude testpulses if the respective information is provided.
‘trigger_ts’ is a list of trigger timestamp lists for each channel that was triggered and ‘trigger_phs’ are the corresponding trigger pulse heights (with identical structure). If some channels are not triggered but read out in coincidence (i.e. as ‘passive’ channels), you can specify the number of such channels using ‘n_passive_ch’.
Events are build as follows: Starting from the first list of timestamps in ‘trigger_ts’, the remaining lists are checked to be in coincidence with already existing timestamps. The default coincidence window (if
interval=None), is-+dt_us*record_length//4but can be adapted as needed.If you provide ‘tp_ts’ and ‘tpas’ (have to be both specified or left None), triggers within a record window of a testpulse are treated as testpulses. Note that you have to provide testpulse information for all channels INCLUDING ‘passive’ channels, i.e. ‘tp_ts’ has to have length
len(trigger_ts) + n_passive_ch.- Parameters:
trigger_ts (List[List[int]]) – A list of lists of timestamps of the channels that were triggered.
trigger_phs (List[List[int]]) – A list of lists of triggered pulse heights corresponding to the trigger timestamps above.
record_length (int) – The record length to use for building the events (usually a power of 2).
dt_us (int) – The microsecond timebase that was used in the recording.
n_passive_ch (int, optional) – The number of ‘passive’ channels, i.e. such that were not triggered but are merely read out in coincidence with other channels’ triggers. Defaults to 0, i.e. all channels that are considered were triggered.
tp_ts (List[List[int]], optional) – A list of lists of timestamps of the testpulses corresponding to all channels. This includes ‘passive’ channels! I.e. you need a testpulse list for all triggered AND passive channels. If you don’t have this information for the ‘passive’ channels, just put an empty list. Defaults to None, i.e. no pulses are counted as testpulses in the event building.
tpas (List[List[float]], optional) – A list of lists of testpulse amplitudes of the testpulses corresponding to all channels. This includes ‘passive’ channels! I.e. you need a testpulse list for all triggered AND passive channels. If you don’t have this information for the ‘passive’ channels, just put an empty list. Defaults to None, i.e. no pulses are counted as testpulses in the event building.
interval (Tuple[float], optional) – The coincidence interval for event building in microseconds, i.e. if a trigger lies within the specified interval around a trigger of another channel, they are collected to represent one event. Defaults to
-+dt_us*record_length//4.
- Returns:
event_ts- The timestamps of the events after event building, i.e. checking coincidences with other channels and excluding testpulses (if testpulse information was provided). Has shape(N,).trigger_flag- A boolean flag of dimension(M, N)whereMis the number of channels (including ‘passive’ channels). It is True for whichever event the respective channel triggered. For ‘passive’ channels, this is of course always False.original_ts- Array of dimension(M, N)which stores the original trigger timestamps (before event building). It is set to-1wherever a channel did not trigger.original_ph- Array of dimension(M, N)which stores the original trigger pulse heights (before event building). It is set to-1wherever a channel did not trigger.all_tp_ts- The timestamps of all testpulses of all channels (after event building). Has shape(K,).final_tpas- Array of dimension(M, K)which stores the testpulse amplitudes for all channels at timesall_tp_ts. It is set to404whenever a channel did not receive its own testpulse (but it was sent to another channel).
- Return type:
Tuple[numpy.ndarray]
Trigger functions
- cait.versatile.functions.trigger.triggerbase.trigger_base(stream: _Buffer | _SupportsArray[dtype[Any]] | _NestedSequence[_SupportsArray[dtype[Any]]] | complex | bytes | str | _NestedSequence[complex | bytes | str], threshold: float, filter_fnc: callable, record_length: int, n_triggers: int = None, chunk_size: int = 100, apply_first: callable | List[callable] = None, n_processes: int = None)[source]
Trigger a single channel of a stream after pre-processing the stream. This function is used both for optimum filter triggering as well as for z-score triggering. See below for a description on how the algorithm works.
- Parameters:
stream (ArrayLike) – The stream channel to trigger.
threshold (float) – The threshold above which events should be triggered (interpretation depends on ‘filter_fnc’).
filter_fnc (callable) – The function to be applied to the data before triggering.
record_length (int) – The desired record length (this determines the dead-time after a trigger)
n_triggers (int) – The number of events to trigger (might be more, depending on ‘chunk_size’). E.g. useful to look at the first 100 triggered events. Defaults to None, i.e. all events in the stream are triggered
chunk_size (int) – The number of record windows that are processed (i.e. filter + peak search) at a time.
apply_first (Union[callable, List[callable]], optional) – A function or list of functions to be applied to the stream data BEFORE the filter function is applied. E.g.
lambda x: -xto trigger on the inverted stream.n_processes (int, optional) – The number of processes to use to process chunks. If None,
cait._available_workersis used. Defaults to None
- Returns:
Tuple of trigger indices and trigger heights.
- Return type:
Tuple[List[int], List[float]]
Description of the Trigger Algorithm:
The stream is split into (not necessarily equally sized) chunks which are processed at once. This reduces file access and larger chunks are generally preferred if sufficient memory is available. To correctly filter a chunk (optimum filtering or moving z-score), an additional record window before the chunk is needed (because the filter length is one record length). For this reason, the very first record window of the stream is discarded, i.e. not searched for triggers. Additionally, one record window after the chunk ends is required to not miss any edge cases as marked with numbers 1-3 in the figure (see later). We call the start of a chunk \(s\), the end \(e\) and the record length \(N\). The triggering now proceeds as follows:
A chunk is selected and the part of the stream from \(s-N\) to \(e+2N\) is continuously filtered. The first and last record window of the filter output is discarded. The valid samples (\(s\) to \(e+N\)) to be searched for triggers are shown in the figure.
The cursor is placed on the first sample, \(s\), and progresses through the chunk until a sample above threshold is found.
If a sample exceeding the threshold is found, the maximum position of the \(N\) samples after that sample is considered the trigger sample \(j\). The cursor is moved to \(j+N/2\), i.e. the trigger is blinded for half a record window. The process finishes if \(j+N/2\) falls outside the chunk (i.e. \(j+N/2\ge e\)), or if the cursor reaches the end of the chunk, \(e\).
After finishing a chunk, the next one is loaded. We have to be careful not to double count triggers, though: If the last chunk had a trigger later than \(e-N/2\), the blinding process affects the following chunk. This is visualised by triggers 1-3 in the figure: 1 is fine, because more than half a record window remains in the chunk and blinding in the following chunk is not required. 2 and 3 on the other hand require blinding of the first \(j+N/2-e\) samples of the following chunk.
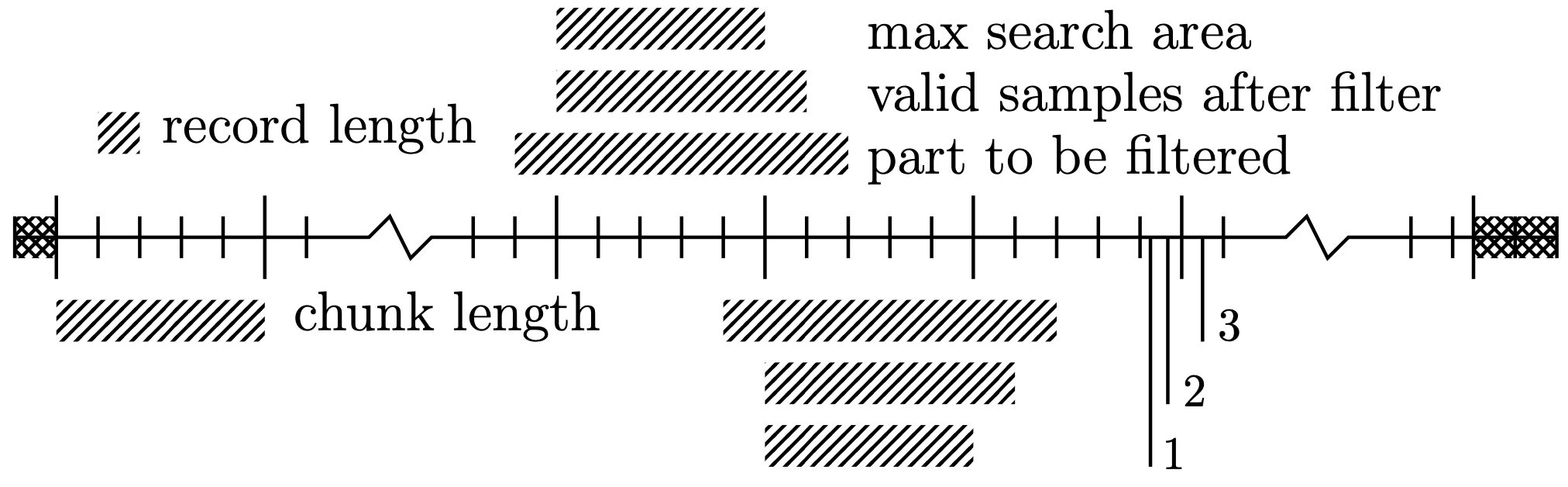
Nota bene:
One could be lead to believe that the additional record window after the end of the chunk is unnecessary, but this would introduce a subtle issue in the triggering process: If we find a sample above threshold at position 1 or 2, we cannot search the following \(N\) samples for a maximum, and if we just stopped the search \(N\) samples before the end of the chunk, we could miss triggers because those samples are not searched in the subsequent chunk either. Therefore, we have to search until we reach \(e\). If we find a sample above threshold just before (or at) \(e\), we still have enough samples left to correctly determine the maximum of the upcoming \(N\) samples.
In the end of the stream we have to discard 2 (!) record windows even though one appears to be sufficient at first glance. As discussed in the previous bullet point, the algorithm described above could lead to a trigger index as late as \(e+N\). To leave enough samples to read the voltage trace of the triggered event in the analysis, an additional record window is kept (even though in the common convention - that the trigger is placed at \(N/4\) in the record window - \(3N/4\) samples would technically be sufficient).
Given the previous two points we want to point out that a trigger can be found in the second to last record window only if the threshold is exceeded before this window starts. Otherwise, a pulse completely located after the beginning of the second to last window is lost. This is a design choice (see previous points).
- cait.versatile.trigger_of(stream: _Buffer | _SupportsArray[dtype[Any]] | _NestedSequence[_SupportsArray[dtype[Any]]] | complex | bytes | str | _NestedSequence[complex | bytes | str], threshold: float, of: ndarray, n_triggers: int = None, chunk_size: int = 100, apply_first: callable | List[callable] = None, n_processes: int = None)[source]
Trigger a single channel of a stream using the optimum filter triggering algorithm described in https://edoc.ub.uni-muenchen.de/23762/. See
cait.versatile.functions.trigger.triggerbase.trigger_base()for details on the implementation.- Parameters:
stream (ArrayLike) – The stream channel to trigger.
threshold (float) – The threshold (in Volts) above which events should be triggered.
of (np.ndarray) – The optimum filter to be used for filtering (it is assumed that the filter’s first entry is set to zero to correctly remove the offset).
n_triggers (int) – The number of events to trigger (might be more, depending on ‘chunk_size’). E.g. useful to look at the first 100 triggered events. Defaults to None, i.e. all events in the stream are triggered
chunk_size (int) – The number of record windows that are processed (i.e. filter + peak search) at a time.
apply_first (Union[callable, List[callable]], optional) – A function or list of functions to be applied to the stream data BEFORE the filter function is applied. E.g.
lambda x: -xto trigger on the inverted stream.n_processes (int, optional) – The number of processes to use to process chunks. If None, all available cores are utilized. Defaults to None
- Returns:
Tuple of trigger indices and trigger heights.
- Return type:
Tuple[List[int], List[float]]
Example:
import cait.versatile as vai # Construct stream object stream = vai.Stream(hardware="vdaq2", src="path/to/stream_file.bin") # Get an optimum filter from somewhere (here, we get one from mock data but # this will not work for your stream data) of = vai.MockData().of # Perform triggering (use context to keep stream file opened) with stream: trigger_inds, amplitudes = vai.trigger_of(stream["ADC1"], 0.1, of) # Get trigger timestamps from trigger indices timestamps = stream.time[trigger_inds] # Plot trigger amplitude spectrum vai.Histogram(amplitudes)
- cait.versatile.trigger_of2d(stream: _Buffer | _SupportsArray[dtype[Any]] | _NestedSequence[_SupportsArray[dtype[Any]]] | complex | bytes | str | _NestedSequence[complex | bytes | str], threshold: float, of: ndarray, n_triggers: int = None, chunk_size: int = 100, apply_first: callable | List[callable] = None, n_processes: int = None)[source]
Trigger multiple channels of a stream at the same time using a 2D optimum filter and the optimum filter triggering algorithm described in https://edoc.ub.uni-muenchen.de/23762/. See
cait.versatile.functions.trigger.triggerbase.trigger_base()for details on the implementation. The correlated filtering returns A SINGLE voltage trace (even for multiple input channels), hence, only a combined trigger threshold is required.Apart from the fact that multi-channel ‘streams’ and ‘of2d’ are required here, the usage is identical to
cait.versatile.trigger_of().- Parameters:
stream (ArrayLike) – The stream channels to trigger (The ‘channel’ returns 2d-arrays. Usually, one would get this using
stream[('Ch0', 'Ch1')]).threshold (float) – The threshold (in Volts) above which events should be triggered.
of (np.ndarray) – The correlated (2d) optimum filter to be used for filtering (it is assumed that the filter’s first entry is set to zero to correctly remove the offset).
n_triggers (int) – The number of events to trigger (might be more, depending on ‘chunk_size’). E.g. useful to look at the first 100 triggered events. Defaults to None, i.e. all events in the stream are triggered
chunk_size (int) – The number of record windows that are processed (i.e. filter + peak search) at a time.
apply_first (Union[callable, List[callable]], optional) – A function or list of functions to be applied to the stream data BEFORE the filter function is applied. E.g.
lambda x: -xto trigger on the inverted stream.n_processes (int, optional) – The number of processes to use to process chunks. If None, all available cores are utilized. Defaults to None
- Returns:
Tuple of trigger indices and trigger heights.
- Return type:
Tuple[List[int], List[float]]
- cait.versatile.trigger_zscore(stream: _Buffer | _SupportsArray[dtype[Any]] | _NestedSequence[_SupportsArray[dtype[Any]]] | complex | bytes | str | _NestedSequence[complex | bytes | str], record_length: int, threshold: float = 5, n_triggers: int = None, chunk_size: int = 100, apply_first: callable | List[callable] = None, n_processes: int = None)[source]
Trigger a single channel of a stream using a moving z-score. See
cait.versatile.functions.trigger.triggerbase.trigger_base()for details on the implementation.- Parameters:
stream (ArrayLike) – The stream channel to trigger.
threshold (float) – The threshold (in z-scores) above which events should be triggered.
n_triggers (int) – The number of events to trigger (might be more, depending on ‘chunk_size’). E.g. useful to look at the first 100 triggered events. Defaults to None, i.e. all events in the stream are triggered
chunk_size (int) – The number of record windows that are processed (i.e. z-score calculation + peak search) at a time.
apply_first (Union[callable, List[callable]], optional) – A function or list of functions to be applied to the stream data BEFORE the filter function is applied. E.g.
lambda x: -xto trigger on the inverted stream.n_processes (int, optional) – The number of processes to use to process chunks. If None, all available cores are utilized. Defaults to None
- Returns:
Tuple of trigger indices and trigger heights.
- Return type:
Tuple[List[int], List[float]]
Example:
import cait.versatile as vai # Construct stream object stream = vai.Stream(hardware="vdaq2", src="path/to/stream_file.bin") # Perform triggering (use context to keep stream file opened) with stream: trigger_inds, amplitudes = vai.trigger_zscore(stream["ADC1"], 2**14) # Get trigger timestamps from trigger indices timestamps = stream.time[trigger_inds] # Plot trigger amplitude spectrum vai.Histogram(amplitudes)